Redis分片集群搭建学习心得(入门)
*这里的入门版为在windows单机系统下,作为入门学习。真正的开发应该将多个结点分别部署在不同的服务器上,这样才能真正做到高可用性。
介绍
Redis的集群分为3种:主从集群,哨兵集群,分片集群;个人理解分为两类,主从和哨兵归为一类,因为哨兵集群和主从集群配合使用。
分片集群特点:具有高可用性,负载均衡特点,支持散列插槽,集群伸缩和故障转移功能。
搭建分片集群
*分片集群最少需要三个主节点,这里展示三主三从,搭建最小集群
集群结点信息:
创建存放六个结点的文件夹并且重命名
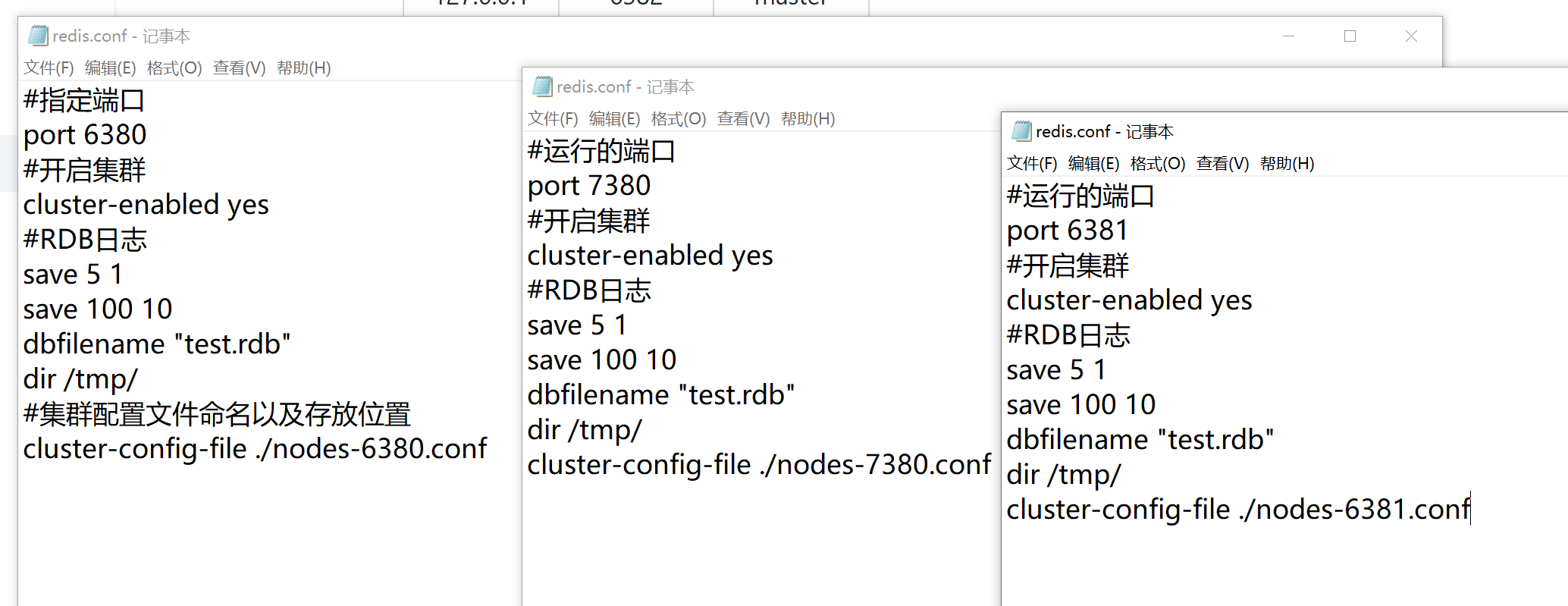
在各自的文件夹下创建配置文件"redis.conf",配置文件信息如下:
#指定端口
port 6380
#开启集群
cluster-enabled yes
#RDB日志
save 5 1
save 100 10
dbfilename "test.rdb"
dir /tmp/
#集群配置文件命名以及存放位置
cluster-config-file ./nodes-6380.conf端口号以及集群配置文件名改为对应的端口号以示区分
3.启动六个结点,这里使用了终端管理工具一键启动
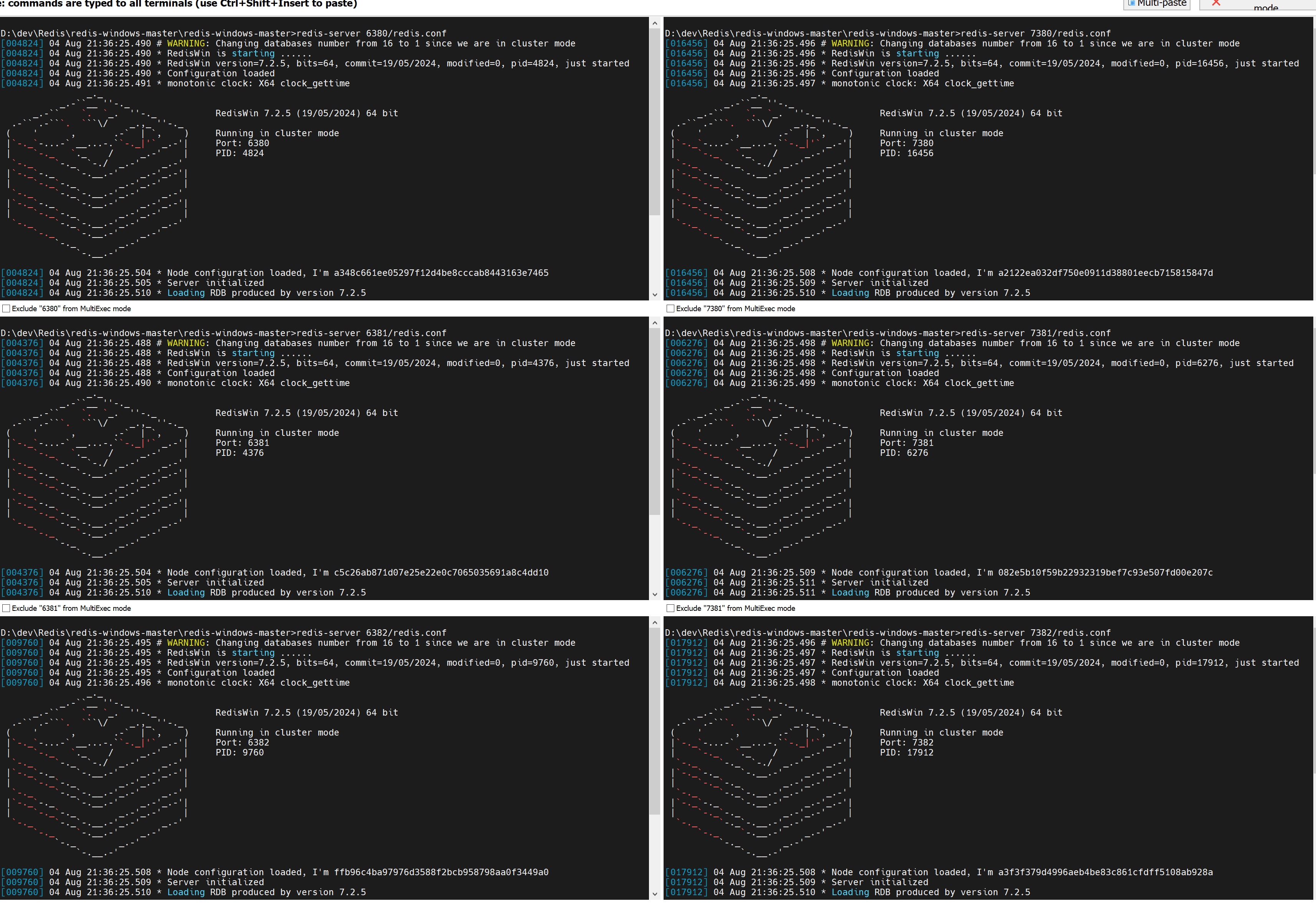
现在仅仅启动了6个结点,他们之间并没有产生关系,还需要创建集群
启动命令
解释:
--cluster create :创建集群
--cluster-replicas 1:因为这里是 三主三从结构,指定数字“1”表示一个主节点只分配一个从节点;在输入地址时我们默认先输入三个主节点的ip,随后在输入三个从节点的信息,这样redis集群就会自动管理响应的主从信息
redis-cli --cluster create --cluster-replicas 1 127.0.0.1:6380 12
7.0.0.1:6381 127.0.0.1:6382 127.0.0.1:7380 127.0.0.1:7381 127.0.0.1:7382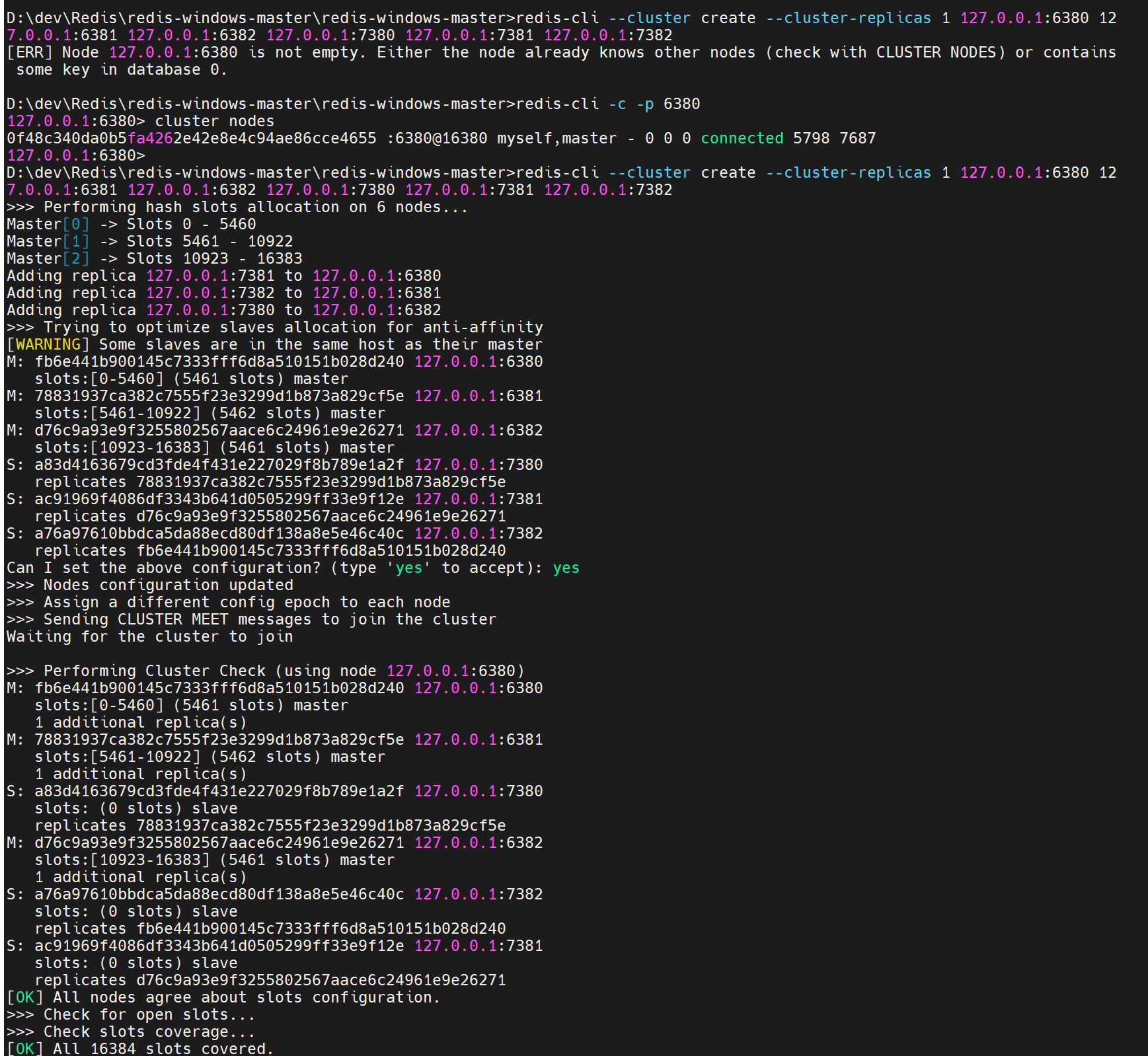
现在Redis的分片集群就启动起来了
散列插槽,集群伸缩,故障转移
散列插槽:在分片集群中,数据并不存放在结点上,这是因为结点出现故障后数据就丢失了,为了保证数据的可用性,redis分片集群将数据和插槽绑定。
1.现在连接了6380端口
2.设置“name”的值为“jack”,这里分片集群将“name”属性重定向到了6381端口下的5798槽位,这样当结点发生故障的之后,插槽会被分配到正常的结点上,从而将数据保护了起来
集群伸缩:分片集群的另一个独特优点就是内存扩容,当增加/删除一个节点能实现动态的集群伸缩
步骤:首先新增一个节点7384,然后将6380节点的800个槽位分配到7384节点
redis-cli --cluster add-node 127.0.0.1:7384 127.0.0.1:7380 #新增节点到集群
redis-cli --cluster reshard 127.0.0.1:6380 #拆分6380的槽位
#输入完上面命令后会自动给出交互式输入
How many slots do you want to move (from 1 to 16384)? 800
What is the receiving node ID? 74634bf72ecfed2c00e839b7cafafd19564a0e71 #接收节点也就是7384的id
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: eb6a6efb9db70ece64abb216a74f5d64f409f6a4 #源节点也就是6380的id
Source node #2: done #输入done后开始分配===槽位移动过程===
3.故障转移:当某一结点出现故障时,Redis集群会自动进行故障转移,如果是主节点发生故障,他的从结点们会自动选举其中一个为主节点,实现了奴隶翻身做主人。
也可以手动故障转移,当需要一个从节点接替主节点时,连接到从节点后执行 命令 --cluster failover 即可