设计模式-观察者模式最佳实践
设计模式是什么?
在软件开发中,设计模式是解决常见问题的可复用解决方案。它们不是具体的代码,而是一套经过验证的设计和架构方法,可以帮助开发者更好地组织代码结构、提高代码质量、并降低系统的复杂性。 设计模式的重要性 解决通用问题: 设计模式提供了解决常见设计问题的标准化方法。通过运用这些模式,开发者不需要每次都重新发明轮子,可以直接借鉴已有的成熟解决方案,从而节省时间。 提高代码的可维护性: 设计模式鼓励开发者编写可扩展、易维护的代码。通过结构化的设计,后续的代码修改、扩展变得更加容易,减少了开发过程中的返工和技术债务。 增强代码的可读性: 设计模式为团队成员提供了一个共同的语言。当开发者提到“工厂模式”或“观察者模式”时,团队中其他开发者可以快速理解代码意图,而无需深入研究具体实现细节。 应对系统的变化和扩展: 软件项目通常需要随着业务需求的变化而不断扩展。设计模式帮助开发者设计具有良好扩展性的系统,能够应对变化而不需要对现有代码进行大量修改。 减少开发中的错误: 由于设计模式是经过多次实践验证的解决方案,使用这些模式可以避免一些典型的错误,比如对象之间紧耦合、依赖不稳定等。 如何认知设计模式 设计模式的三大类型: 设计模式大致可以分为三类: 创建型模式:解决对象实例化的问题,确保对象创建的灵活性和控制性。典型模式包括工厂模式、单例模式等。 结构型模式:关注对象之间的关系,帮助你以更灵活的方式组织代码。常见的有装饰器模式、代理模式、适配器模式等。 行为型模式:侧重对象之间的交互和职责分配,如观察者模式、策略模式、责任链模式等。 理解模式的意图: 学习设计模式时,关键是理解每个模式的意图,即它是为了解决什么问题的。不要机械地背诵模式的定义,而是要理解在什么情况下使用它能够带来好处。 设计模式的灵活性: 设计模式提供的是指导思想,而不是必须严格遵循的规则。在实际项目中,开发者可以根据具体情况灵活运用,甚至将多个模式结合起来使用。 如何学习设计模式 学习经典书籍: 最著名的设计模式书籍是《设计模式:可复用面向对象软件的基础》(Design Patterns: Elements of Reusable Object-Oriented Software),俗称“四人帮”(GoF)的设计模式。它详细介绍了23种经典设计模式,是设计模式学习的奠基之作。 理解实践中的应用: 读书只能提供理论知识,要真正掌握设计模式,需要将其应用到实际项目中。你可以在编写代码时,刻意尝试使用某个设计模式,理解其优势和局限性。 代码阅读与分析: 研究开源项目的源码是学习设计模式的好方法。许多优秀的开源项目都应用了设计模式,通过分析这些项目中的设计,你可以学到设计模式的实际应用。 通过重构来理解: 在学习过程中,可以尝试重构已有代码。例如,将原本紧耦合的代码改造成使用观察者模式的事件驱动结构,这样的实践会加深对设计模式的理解。 逐步引入模式: 不要在项目的每个地方都强行使用设计模式,而是随着项目的增长逐步引入。例如,最开始你可能只需要一个简单的工厂方法,之后随着需求增加,可以引入策略模式或责任链模式来解耦不同模块之间的逻辑。 与同行讨论: 通过与其他开发者交流设计模式的使用心得,了解别人是如何运用这些模式的,能够拓展你的思路,发现新的应用场景和技巧。 总结 设计模式是软件开发中的一套重要的工具,它们提供了结构化的解决方案来应对代码的复杂性和变化。要深入理解和掌握设计模式,除了学习理论,更要通过实践、分析和讨论,不断提升对模式的认识。通过对设计模式的熟练应用,开发者可以编写出更清晰、可扩展和可维护的代码,从而大大提高开发效率和代码质量。
以上由ChatGPT回答,GPT的回答其实已经相对简介明了地介绍了什么是设计模式。设计模式简而言之是解决常见问题的可复用解决方案。它们不是具体的代码,而是一套经过验证的设计和架构方法。那么我们想应用设计模式那么首先要明确问题场景,根据不同的问题来选择不同的设计模式来解决问题。
既然我们知晓了这个设计模式是什么,用来解决什么问题;那么我们接下来则应该考虑如何正确应用其并将其发挥最大效用。要应用设计模式,首先我们要了解设计模式一共有多少种,分几类,要符合哪些原则。
七项基本原则
单一职责原则 (Single Responsibility Principle)
单一职责原则表示一个模块的组成元素之间的功能相关性。从软件变化的角度来看,就一个类而言,应该仅有一个让它变化的原因;通俗地说,即一个类只负责一项职责。
假设某个类 P 负责两个不同的职责,职责 P1 和 职责 P2,那么当职责 P1 需求发生改变而需要修改类 P,有可能会导致原来运行正常的职责 P2 功能发生故障。
我们假设一个场景:
有一个动物类,它会呼吸空气,用一个类描述动物呼吸这个场景:
class Animal{
public void breathe(String animal){
System.out.println(animal + "呼吸空气");
}
}
public class Client{
public static void main(String[] args){
Animal animal = new Animal();
animal.breathe("牛");
animal.breathe("羊");
animal.breathe("猪");
}
}
在后来发现新问题,并不是所有的动物都需要呼吸空气,比如鱼需要呼吸水,修改时如果遵循单一职责原则的话,那么需要将 Animal 类进行拆分为陆生类和水生动物类,代码如下:
class Terrestrial{
public void breathe(String animal){
System.out.println(animal + "呼吸空气");
}
}
class Aquatic{
public void breathe(String animal){
System.out.println(animal + "呼吸水");
}
}
public class Client{
public static void main(String[] args){
Terrestrial terrestrial = new Terrestrial();
terrestrial.breathe("牛");
terrestrial.breathe("羊");
terrestrial.breathe("猪");
Aquatic aquatic = new Aquatic();
aquatic.breathe("鱼");
}
}
在实际工作中,如果这样修改的话开销是很大的,除了将原来的 Animal 类分解为 Terrestrial 类和 Aquatic 类以外还需要修改客户端,而直接修改类 Animal 类来达到目的虽然违背了单一职责原则,但是花销却小的多,代码如下:
class Animal{
public void breathe(String animal){
if("鱼".equals(animal)){
System.out.println(animal + "呼吸水");
}else{
System.out.println(animal + "呼吸空气");
}
}
}
public class Client{
public static void main(String[] args){
Animal animal = new Animal();
animal.breathe("牛");
animal.breathe("羊");
animal.breathe("猪");
animal.breathe("鱼");
}
}
可以看得出,这样的修改显然简便了许多,但是却存在着隐患,如果有一天有需要加入某类动物不需要呼吸,那么就要修改 Animal 类的 breathe 方法,而对原有代码的修改可能会对其他相关功能带来风险,也许有一天你会发现输出结果变成了:"牛呼吸水" 了,这种修改方式直接在代码级别上违背了单一职责原则,虽然修改起来最简单,但隐患却最大的。
另外还有一种修改方式:
class Animal{
public void breathe(String animal){
System.out.println(animal + "呼吸空气");
}
public void breathe2(String animal){
System.out.println(animal + "呼吸水");
}
}
public class Client{
public static void main(String[] args){
Animal animal = new Animal();
animal.breathe("牛");
animal.breathe("羊");
animal.breathe("猪");
animal.breathe2("鱼");
}
}
可以看出,这种修改方式没有改动原来的代码,而是在类中新加了一个方法,这样虽然违背了单一职责原则,但是它并没有修改原来已存在的代码,不会对原本已存在的功能造成影响。
那么在实际编程中,需要根据实际情况来确定使用哪种方式,只有逻辑足够简单,才可以在代码级别上违背单一职责原则。
总结:
SRP 是一个简单又直观的原则,但是在实际编码的过程中很难将它恰当地运用,需要结合实际情况进行运用。
单一职责原则可以降低类的复杂度,一个类仅负责一项职责,其逻辑肯定要比负责多项职责简单。
提高了代码的可读性,提高系统的可维护性。
开放-关闭原则 (Open-Closed Principle)
开放-关闭原则表示软件实体 (类、模块、函数等等) 应该是可以被扩展的,但是不可被修改。(Open for extension, close for modification)
如果一个软件能够满足 OCP 原则,那么它将有两项优点:
能够扩展已存在的系统,能够提供新的功能满足新的需求,因此该软件有着很强的适应性和灵活性。
已存在的模块,特别是那些重要的抽象模块,不需要被修改,那么该软件就有很强的稳定性和持久性。
举个简单例子,这里有个生产电脑的公司,根据输入的类型,生产出不同的电脑,代码如下:
interface Computer {}
class Macbook implements Computer {}
class Surface implements Computer {}
class Factory {
public Computer produceComputer(String type) {
Computer c = null;
if(type.equals("macbook")){
c = new Macbook();
}else if(type.equals("surface")){
c = new Surface();
}
return c;
}
}
显然上面的代码违背了开放 - 关闭原则,如果需要添加新的电脑产品,那么修改 produceComputer 原本已有的方法,正确的方式如下:
interface Computer {}
class Macbook implements Computer {}
class Surface implements Computer {}
interface Factory {
public Computer produceComputer();
}
class AppleFactory implements Factory {
public Computer produceComputer() {
return new Macbook();
}
}
class MSFactory implements Factory {
public Computer produceComputer() {
return new Surface();
}
}
正确的方式应该是将 Factory 抽象成接口,让具体的工厂(如苹果工厂,微软工厂)去实现它,生产它们公司相应的产品,这样写有利于扩展,如果这是需要新增加戴尔工厂生产戴尔电脑,我们仅仅需要创建新的电脑类和新的工厂类,而不需要去修改已经写好的代码。
总结:
OCP 可以具有良好的可扩展性,可维护性。
不可能让一个系统的所有模块都满足 OCP 原则,我们能做到的是尽可能地不要修改已经写好的代码,已有的功能,而是去扩展它。
里氏替换原则 (Liskov Substitution Principle)
编程中常常会遇到这样的问题:有一功能 P1, 由类 A 完成,现需要将功能 P1 进行扩展,扩展后的功能为 P,其中P由原有功能P1与新功能P2组成。新功能P由类A的子类B来完成,则子类B在完成新功能P2的同时,有可能会导致原有功能P1发生故障。
里氏替换原则告诉我们,当使用继承时候,类 B 继承类 A 时,除添加新的方法完成新增功能 P2,尽量不要修改父类方法预期的行为。
里氏替换原则的重点在不影响原功能,而不是不覆盖原方法。
继承包含这样一层含义:父类中凡是已经实现好的方法(相对于抽象方法而言),实际上是在设定一系列的规范和契约,虽然它不强制要求所有的子类必须遵从这些契约,但是如果子类对这些非抽象方法任意修改,就会对整个继承体系造成破坏。而里氏替换原则就是表达了这一层含义。
举个例子,我们需要完成一个两数相减的功能:
class A{
public int func1(int a, int b){
return a-b;
}
}
后来,我们需要增加一个新的功能:完成两数相加,然后再与100求和,由类B来负责。即类B需要完成两个功能:
两数相减
两数相加,然后再加100
由于类A已经实现了第一个功能,所以类B继承类A后,只需要再完成第二个功能就可以了,代码如下:
class B extends A{
public int func1(int a, int b){
return a+b;
}
public int func2(int a, int b){
return func1(a,b)+100;
}
}
我们发现原来原本运行正常的相减功能发生了错误,原因就是类 B 在给方法起名时无意中重写了父类的方法,造成了所有运行相减功能的代码全部调用了类 B 重写后的方法,造成原来运行正常的功能出现了错误。在实际编程中,我们常常会通过重写父类的方法来完成新的功能,这样写起来虽然简单,但是这样往往也增加了重写父类方法所带来的风险。
里氏替换原则通俗的来讲就是:子类可以扩展父类的功能,但不能改变父类原有的功能。
依赖倒转原则 (Dependence Inversion Principle)
定义:高层模块不应该依赖低层模块,二者都应该于抽象。进一步说,抽象不应该依赖于细节,细节应该依赖于抽象。
举个例子, 某天产品经理需要添加新的功能,该功能需要操作数据库,一般负责封装数据库操作的和处理业务逻辑分别由不同的程序员编写。
封装数据库操作可认为低层模块,而处理业务逻辑可认为高层模块,那么如果处理业务逻辑需要等到封装数据库操作的代码写完的话才能添加的话讲会严重拖垮项目的进度。
正确的做法应该是处理业务逻辑的程序员提供一个封装好数据库操作的抽象接口,交给低层模块的程序员去编写,这样双方可以单独编写而互不影响。
依赖倒转原则的核心思想就是面向接口编程,思考下面这样一个场景:母亲给孩子讲故事,只要给她一本书,她就可照着书给孩子讲故事了。代码如下:
class Book{
public String getContent(){
return "这是一个有趣的故事";
}
}
class Mother{
public void say(Book book){
System.out.println("妈妈开始讲故事");
System.out.println(book.getContent());
}
}
public class Client{
public static void main(String[] args){
Mother mother = new Mother();
mother.say(new Book());
}
}
假如有一天,给的是一份报纸,而不是一本书,让这个母亲讲下报纸上的故事,报纸的代码如下:
class Newspaper{
public String getContent(){
return "这个一则重要的新闻";
}
}
然而这个母亲却办不到,应该她只会读书,这太不可思议,只是将书换成报纸,居然需要修改 Mother 类才能读,假如以后需要换成了杂志呢?原因是 Mother 和 Book 之间的耦合度太高了,必须降低他们的耦合度才行。
我们可以引入一个抽象接口 IReader 读物,让书和报纸去实现这个接口,那么无论提供什么样的读物,该母亲都能读。代码如下:
interface IReader{
public String getContent();
}
class Newspaper implements IReader {
public String getContent(){
return "这个一则重要的新闻";
}
}
class Book implements IReader{
public String getContent(){
return "这是一个有趣的故事";
}
}
class Mother{
public void say(IReader reader){
System.out.println("妈妈开始讲故事");
System.out.println(reader.getContent());
}
}
public class Client{
public static void main(String[] args){
Mother mother = new Mother();
mother.say(new Book());
mother.say(new Newspaper());
}
}
这样修改之后,以后无论提供什么样的读物,只要去实现了 IReader 接口之后就可以被母亲读。实际情况中,代表高层模块的 Mother 类将负责完成主要的业务逻辑,一旦需要对它进行修改,引入错误的风险极大。所以遵循依赖倒转原则可以降低类之间的耦合性,提高系统的稳定性,降低修改程序造成的风险。
依赖倒转原则的核心就是要我们面向接口编程,理解了面向接口编程,也就理解了依赖倒转。
接口隔离原则 (Interface Segregation Principle)
接口隔离原则,其 "隔离" 并不是准备的翻译,真正的意图是 “分离” 接口(的功能)
接口隔离原则强调:客户端不应该依赖它不需要的接口;一个类对另一个类的依赖应该建立在最小的接口上。
我们先来看一张图:
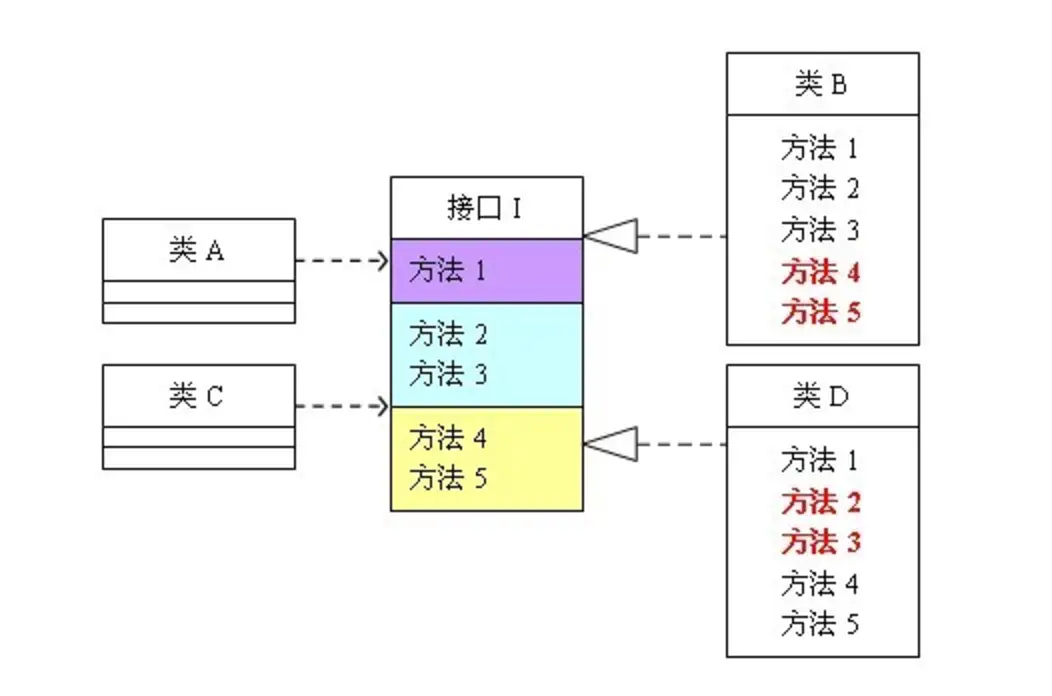
从图中可以看出,类 A 依赖于 接口 I 中的方法 1,2,3 ,类 B 是对类 A 的具体实现。类 C 依赖接口 I 中的方法 1,4,5,类 D 是对类 C 的具体实现。对于类B和类D来说,虽然他们都存在着用不到的方法(也就是图中红色字体标记的方法),但由于实现了接口I,所以也必须要实现这些用不到的方法。
用代码表示:
interface I {
public void method1();
public void method2();
public void method3();
public void method4();
public void method5();
}
class A{
public void depend1(I i){
i.method1();
}
public void depend2(I i){
i.method2();
}
public void depend3(I i){
i.method3();
}
}
class B implements I{
// 类 B 只需要实现方法 1,2, 3,而其它方法它并不需要,但是也需要实现
public void method1() {
System.out.println("类 B 实现接口 I 的方法 1");
}
public void method2() {
System.out.println("类 B 实现接口 I 的方法 2");
}
public void method3() {
System.out.println("类 B 实现接口 I 的方法 3");
}
public void method4() {}
public void method5() {}
}
class C{
public void depend1(I i){
i.method1();
}
public void depend2(I i){
i.method4();
}
public void depend3(I i){
i.method5();
}
}
class D implements I{
// 类 D 只需要实现方法 1,4,5,而其它方法它并不需要,但是也需要实现
public void method1() {
System.out.println("类 D 实现接口 I 的方法 1");
}
public void method2() {}
public void method3() {}
public void method4() {
System.out.println("类 D 实现接口 I 的方法 4");
}
public void method5() {
System.out.println("类 D 实现接口 I 的方法 5");
}
}
public class Client{
public static void main(String[] args){
A a = new A();
a.depend1(new B());
a.depend2(new B());
a.depend3(new B());
C c = new C();
c.depend1(new D());
c.depend2(new D());
c.depend3(new D());
}
}
可以看出,如果接口定义的过于臃肿,只要接口中出现的方法,不管依赖于它的类是否需要该方法,实现类都必须去实现这些方法,这就不符合接口隔离原则,如果想符合接口隔离原则,就必须对接口 I 如下图进行拆分:
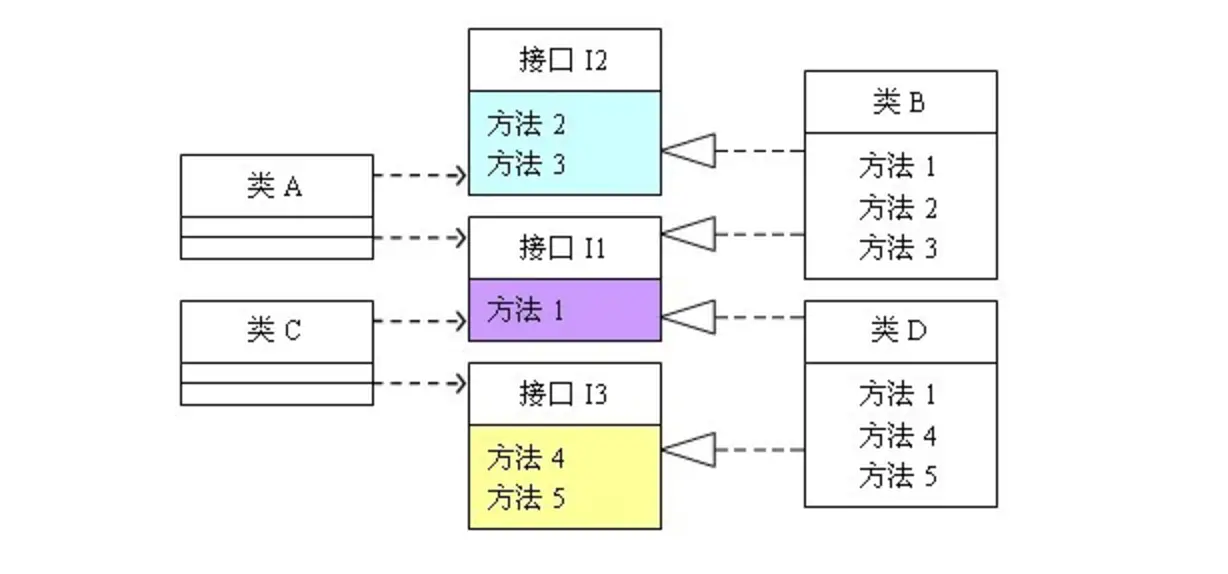
代码可修改为如下:
interface I1 {
public void method1();
}
interface I2 {
public void method2();
public void method3();
}
interface I3 {
public void method4();
public void method5();
}
class A{
public void depend1(I1 i){
i.method1();
}
public void depend2(I2 i){
i.method2();
}
public void depend3(I2 i){
i.method3();
}
}
class B implements I1, I2{
public void method1() {
System.out.println("类 B 实现接口 I1 的方法 1");
}
public void method2() {
System.out.println("类 B 实现接口 I2 的方法 2");
}
public void method3() {
System.out.println("类 B 实现接口 I2 的方法 3");
}
}
class C{
public void depend1(I1 i){
i.method1();
}
public void depend2(I3 i){
i.method4();
}
public void depend3(I3 i){
i.method5();
}
}
class D implements I1, I3{
public void method1() {
System.out.println("类 D 实现接口 I1 的方法 1");
}
public void method4() {
System.out.println("类 D 实现接口 I3 的方法 4");
}
public void method5() {
System.out.println("类 D 实现接口 I3 的方法 5");
}
}
总结:
接口隔离原则的思想在于建立单一接口,尽可能地去细化接口,接口中的方法尽可能少
但是凡事都要有个度,如果接口设计过小,则会造成接口数量过多,使设计复杂化。所以一定要适度。
迪米特法则(Law Of Demeter)
迪米特法则又称为 最少知道原则,它表示一个对象应该对其它对象保持最少的了解。通俗来说就是,只与直接的朋友通信。
首先来解释一下什么是直接的朋友:每个对象都会与其他对象有耦合关系,只要两个对象之间有耦合关系,我们就说这两个对象之间是朋友关系。耦合的方式很多,依赖、关联、组合、聚合等。其中,我们称出现成员变量、方法参数、方法返回值中的类为直接的朋友,而出现在局部变量中的类则不是直接的朋友。也就是说,陌生的类最好不要作为局部变量的形式出现在类的内部。
对于被依赖的类来说,无论逻辑多么复杂,都尽量的将逻辑封装在类的内部,对外提供 public 方法,不对泄漏任何信息。
举个例子,家人探望犯人
家人:家人只与犯人是亲人,但是不认识他的狱友
public class Family {
public void visitPrisoner(Prisoners prisoners) {
Inmates inmates = prisoners.helpEachOther();
imates.weAreFriend();
}
}
犯人:犯人与家人是亲人,犯人与狱友是朋友
public class Prisoners {
private Inmates inmates = new Inmates();
public Inmates helpEachOther() {
System.out.println("家人说:你和狱友之间应该互相帮助...");
return inmates;
}
}
狱友: 犯人与狱友是朋友,但是不认识他的家人
public class Inmates {
public void weAreFriend() {
System.out.println("狱友说:我们是狱友...");
}
}
场景类:发生在监狱里
public class Prison {
public static void main(String args[])
{
Family family = new Family();
family.visitPrisoner(new Prisoners());
}
}
运行结果会发现:
家人说:你和狱友之间应该互相帮助...
狱友说:我们是狱友...
家人和狱友显然是不认识的,且监狱只允许家人探望犯人,而不是随便谁都可以见面的,这里家人和狱友有了沟通显然是违背了迪米特法则,因为在 Inmates 这个类作为局部变量出现在了 Family 类中的方法里,而他们不认识,不能够跟直接通信,迪米特法则告诉我们只与直接的朋友通信。所以上述的代码可以改为:
public class Family {
//家人探望犯人
public void visitPrisoner(Prisoners prisoners) {
System.out.print("家人说:");
prisoners.helpEachOther();
}
}
public class Prisoners {
private Inmates inmates = new Inmates();
public Inmates helpEachOther() {
System.out.println("犯人和狱友之间应该互相帮助...");
System.out.print("犯人说:");
inmates.weAreFriend();
return inmates;
}
}
public class Inmates {
public void weAreFriend() {
System.out.println("我们是狱友...");
}
}
public class Prison {
public static void main(String args[]) {
Family family = new Family();
family.visitPrisoner(new Prisoners());
}
}
运行结果
家人说:犯人和狱友之间应该互相帮助...
犯人说:我们是狱友...
这样家人和狱友就分开了,但是也表达了家人希望狱友能跟犯人互相帮助的意愿。也就是两个类通过第三个类实现信息传递, 而家人和狱友却没有直接通信。
组合/聚合复用原则 (Composite/Aggregate Reuse Principle)
组合/聚合复用原则就是在一个新的对象里面使用一些已有的对象,使之成为新对象的一部分; 新的对象通过向这些对象的委派达到复用已有功能的目的。
在面向对象的设计中,如果直接继承基类,会破坏封装,因为继承将基类的实现细节暴露给子类;如果基类的实现发生了改变,则子类的实现也不得不改变;从基类继承而来的实现是静态的,不可能在运行时发生改变,没有足够的灵活性。于是就提出了组合/聚合复用原则,也就是在实际开发设计中,尽量使用组合/聚合,不要使用类继承。
举个简单的例子,在某家公司里的员工分为经理,工作者和销售者。如果画成 UML 图可以表示为:
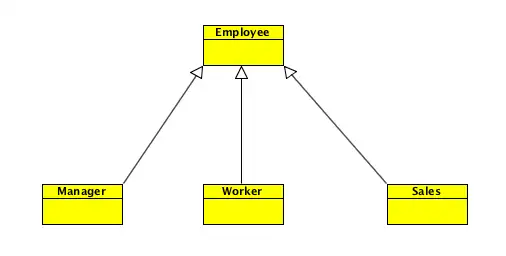
但是这样违背了组合聚合复用原则,继承会将 Employee 类中的方法暴露给子类。如果要遵守组合聚合复用原则,可以将其改为:
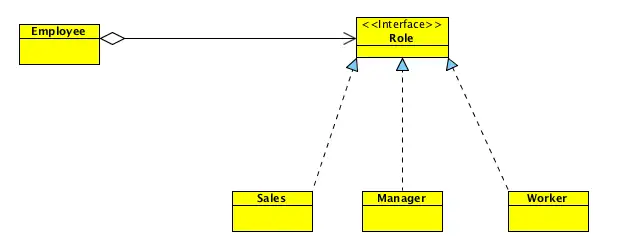
这样做降低了类与类之间的耦合度,Employee 类的变化对其它类造成的影响相对较少。
总结:
总体说来,组合/聚合复用原则告诉我们:组合或者聚合好过于继承。
聚合组合是一种 “黑箱” 复用,因为细节对象的内容对客户端来说是不可见的。
三类设计模式
创建型模式(Creational Pattern):对类的实例化过程进行了抽象,能够将软件模块中对象的创建和对象的使用分离。
(5种)工厂模式、抽象工厂模式、单例模式、建造者模式、原型模式
记忆口诀:创工原单建抽(创公园,但见愁)结构型模式(Structural Pattern):关注于对象的组成以及对象之间的依赖关系,描述如何将类或者对象结合在一起形成更大的结构,就像搭积木,可以通过简单积木的组合形成复杂的、功能更为强大的结构。
(7种)适配器模式、装饰者模式、代理模式、外观模式、桥接模式、组合模式、享元模式
记忆口诀:结享外组适代装桥(姐想外租,世代装桥)行为型模式(Behavioral Pattern):关注于对象的行为问题,是对在不同的对象之间划分责任和算法的抽象化;不仅仅关注类和对象的结构,而且重点关注它们之间的相互作用。
(11种)策略模式、模板方法模式、观察者模式、迭代器模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式
记忆口诀:行状责中模访解备观策命迭(形状折中模仿,戒备观测鸣笛)23种设计模式
创建型模式
创建型模式的作用就是创建对象,说到创建一个对象,最熟悉的就是 new 一个对象,然后 set 相关属性。但是,在很多场景下,我们需要给客户端提供更加友好的创建对象的方式,尤其是那种我们定义了类,但是需要提供给其他开发者用的时候。
简单工厂模式
和名字一样简单,非常简单,直接上代码吧:
public class FoodFactory {
public static Food makeFood(String name) {
if (name.equals("noodle")) {
Food noodle = new LanZhouNoodle();
noodle.addSpicy("more");
return noodle;
} else if (name.equals("chicken")) {
Food chicken = new HuangMenChicken();
chicken.addCondiment("potato");
return chicken;
} else {
return null;
}
}
}
其中,LanZhouNoodle 和 HuangMenChicken 都继承自 Food。
简单地说,简单工厂模式通常就是这样,一个工厂类 XxxFactory,里面有一个静态方法,根据我们不同的参数,返回不同的派生自同一个父类(或实现同一接口)的实例对象。
我们强调职责单一原则,一个类只提供一种功能,FoodFactory 的功能就是只要负责生产各种 Food。
工厂模式
简单工厂模式很简单,如果它能满足我们的需要,我觉得就不要折腾了。之所以需要引入工厂模式,是因为我们往往需要使用两个或两个以上的工厂。
public interface FoodFactory {
Food makeFood(String name);
}
public class ChineseFoodFactory implements FoodFactory {
@Override
public Food makeFood(String name) {
if (name.equals("A")) {
return new ChineseFoodA();
} else if (name.equals("B")) {
return new ChineseFoodB();
} else {
return null;
}
}
}
public class AmericanFoodFactory implements FoodFactory {
@Override
public Food makeFood(String name) {
if (name.equals("A")) {
return new AmericanFoodA();
} else if (name.equals("B")) {
return new AmericanFoodB();
} else {
return null;
}
}
}
其中,ChineseFoodA、ChineseFoodB、AmericanFoodA、AmericanFoodB 都派生自 Food。
客户端调用:
public class APP {
public static void main(String[] args) {
// 先选择一个具体的工厂
FoodFactory factory = new ChineseFoodFactory();
// 由第一步的工厂产生具体的对象,不同的工厂造出不一样的对象
Food food = factory.makeFood("A");
}
}
虽然都是调用 makeFood("A") 制作 A 类食物,但是,不同的工厂生产出来的完全不一样。
第一步,我们需要选取合适的工厂,然后第二步基本上和简单工厂一样。
核心在于,我们需要在第一步选好我们需要的工厂。比如,我们有 LogFactory 接口,实现类有 FileLogFactory 和 KafkaLogFactory,分别对应将日志写入文件和写入 Kafka 中,显然,我们客户端第一步就需要决定到底要实例化 FileLogFactory 还是 KafkaLogFactory,这将决定之后的所有的操作。
虽然简单,不过我也把所有的构件都画到一张图上,这样读者看着比较清晰:

抽象工厂模式
当涉及到产品族的时候,就需要引入抽象工厂模式了。
一个经典的例子是造一台电脑。我们先不引入抽象工厂模式,看看怎么实现。
因为电脑是由许多的构件组成的,我们将 CPU 和主板进行抽象,然后 CPU 由 CPUFactory 生产,主板由 MainBoardFactory 生产,然后,我们再将 CPU 和主板搭配起来组合在一起,如下图:
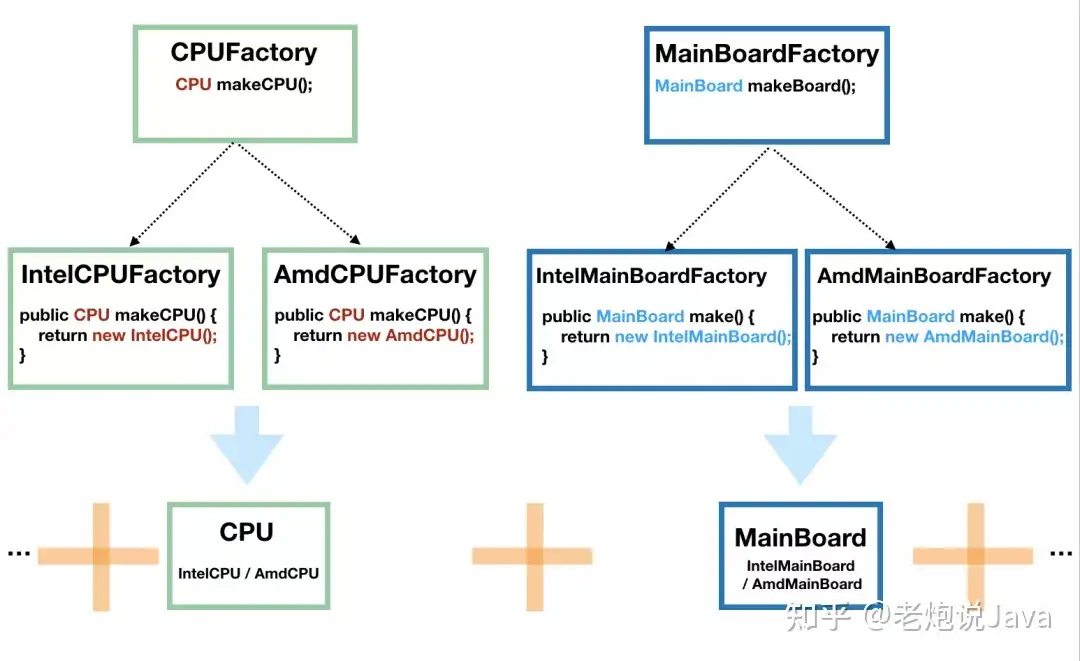
这个时候的客户端调用是这样的:
// 得到 Intel 的 CPU
CPUFactory cpuFactory = new IntelCPUFactory();
CPU cpu = intelCPUFactory.makeCPU();
// 得到 AMD 的主板
MainBoardFactory mainBoardFactory = new AmdMainBoardFactory();
MainBoard mainBoard = mainBoardFactory.make();
// 组装 CPU 和主板
Computer computer = new Computer(cpu, mainBoard);
单独看 CPU 工厂和主板工厂,它们分别是前面我们说的工厂模式。这种方式也容易扩展,因为要给电脑加硬盘的话,只需要加一个 HardDiskFactory 和相应的实现即可,不需要修改现有的工厂。
但是,这种方式有一个问题,那就是如果 Intel 家产的 CPU 和 AMD 产的主板不能兼容使用,那么这代码就容易出错,因为客户端并不知道它们不兼容,也就会错误地出现随意组合。
下面就是我们要说的产品族的概念,它代表了组成某个产品的一系列附件的集合:
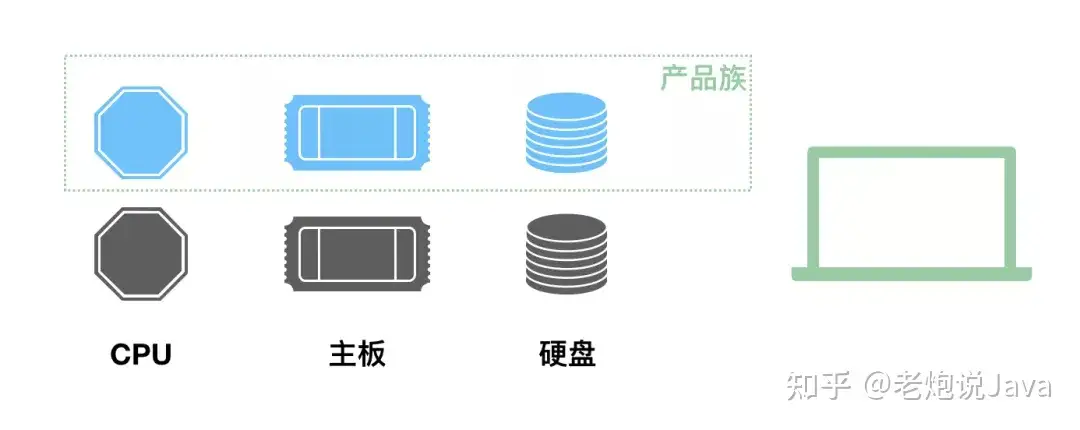
当涉及到这种产品族的问题的时候,就需要抽象工厂模式来支持了。我们不再定义 CPU 工厂、主板工厂、硬盘工厂、显示屏工厂等等,我们直接定义电脑工厂,每个电脑工厂负责生产所有的设备,这样能保证肯定不存在兼容问题。
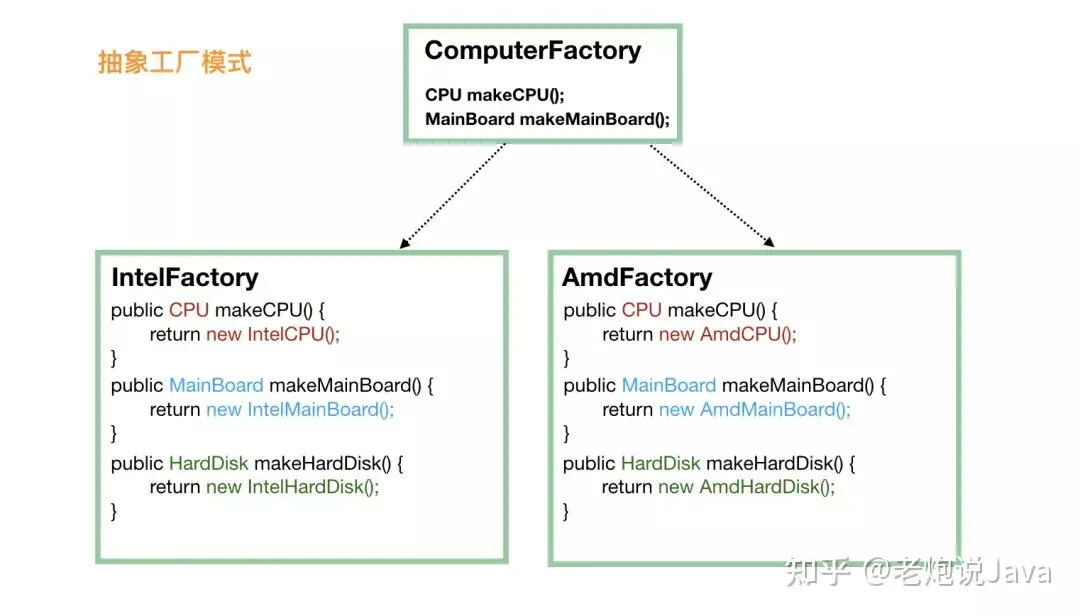
这个时候,对于客户端来说,不再需要单独挑选 CPU厂商、主板厂商、硬盘厂商等,直接选择一家品牌工厂,品牌工厂会负责生产所有的东西,而且能保证肯定是兼容可用的。
public static void main(String[] args) {
// 第一步就要选定一个“大厂”
ComputerFactory cf = new AmdFactory();
// 从这个大厂造 CPU
CPU cpu = cf.makeCPU();
// 从这个大厂造主板
MainBoard board = cf.makeMainBoard();
// 从这个大厂造硬盘
HardDisk hardDisk = cf.makeHardDisk();
// 将同一个厂子出来的 CPU、主板、硬盘组装在一起
Computer result = new Computer(cpu, board, hardDisk);
}
当然,抽象工厂的问题也是显而易见的,比如我们要加个显示器,就需要修改所有的工厂,给所有的工厂都加上制造显示器的方法。这有点违反了对修改关闭,对扩展开放这个设计原则。
单例模式
单例模式用得最多,错得最多。
饿汉模式最简单:
public class Singleton {
// 首先,将 new Singleton() 堵死
private Singleton() {};
// 创建私有静态实例,意味着这个类第一次使用的时候就会进行创建
private static Singleton instance = new Singleton();
public static Singleton getInstance() {
return instance;
}
// 瞎写一个静态方法。这里想说的是,如果我们只是要调用 Singleton.getDate(...),
// 本来是不想要生成 Singleton 实例的,不过没办法,已经生成了
public static Date getDate(String mode) {return new Date();}
}
很多人都能说出饿汉模式的缺点,可是我觉得生产过程中,很少碰到这种情况:你定义了一个单例的类,不需要其实例,可是你却把一个或几个你会用到的静态方法塞到这个类中。
饱汉模式最容易出错:
public class Singleton {
// 首先,也是先堵死 new Singleton() 这条路
private Singleton() {}
// 和饿汉模式相比,这边不需要先实例化出来,注意这里的 volatile,它是必须的
private static volatile Singleton instance = null;
public static Singleton getInstance() {
if (instance == null) {
// 加锁
synchronized (Singleton.class) {
// 这一次判断也是必须的,不然会有并发问题
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
双重检查,指的是两次检查 instance 是否为 null。
volatile 在这里是需要的,希望能引起读者的关注。
很多人不知道怎么写,直接就在 getInstance() 方法签名上加上 synchronized,这就不多说了,性能太差。
嵌套类最经典,以后大家就用它吧:
public class Singleton3 {
private Singleton3() {}
// 主要是使用了 嵌套类可以访问外部类的静态属性和静态方法 的特性
private static class Holder {
private static Singleton3 instance = new Singleton3();
}
public static Singleton3 getInstance() {
return Holder.instance;
}
}
注意,很多人都会把这个嵌套类说成是静态内部类,严格地说,内部类和嵌套类是不一样的,它们能访问的外部类权限也是不一样的。
最后,我们说一下枚举,枚举很特殊,它在类加载的时候会初始化里面的所有的实例,而且 JVM 保证了它们不会再被实例化,所以它天生就是单例的。
虽然我们平时很少看到用枚举来实现单例,但是在 RxJava 的源码中,有很多地方都用了枚举来实现单例。
建造者模式
经常碰见的 XxxBuilder 的类,通常都是建造者模式的产物。建造者模式其实有很多的变种,但是对于客户端来说,我们的使用通常都是一个模式的:
Food food = new FoodBuilder().a().b().c().build();
Food food = Food.builder().a().b().c().build();
套路就是先 new 一个 Builder,然后可以链式地调用一堆方法,最后再调用一次 build() 方法,我们需要的对象就有了。
来一个中规中矩的建造者模式:
class User {
// 下面是“一堆”的属性
private String name;
private String password;
private String nickName;
private int age;
// 构造方法私有化,不然客户端就会直接调用构造方法了
private User(String name, String password, String nickName, int age) {
this.name = name;
this.password = password;
this.nickName = nickName;
this.age = age;
}
// 静态方法,用于生成一个 Builder,这个不一定要有,不过写这个方法是一个很好的习惯,
// 有些代码要求别人写 new User.UserBuilder().a()...build() 看上去就没那么好
public static UserBuilder builder() {
return new UserBuilder();
}
public static class UserBuilder {
// 下面是和 User 一模一样的一堆属性
private String name;
private String password;
private String nickName;
private int age;
private UserBuilder() {
}
// 链式调用设置各个属性值,返回 this,即 UserBuilder
public UserBuilder name(String name) {
this.name = name;
return this;
}
public UserBuilder password(String password) {
this.password = password;
return this;
}
public UserBuilder nickName(String nickName) {
this.nickName = nickName;
return this;
}
public UserBuilder age(int age) {
this.age = age;
return this;
}
// build() 方法负责将 UserBuilder 中设置好的属性“复制”到 User 中。
// 当然,可以在 “复制” 之前做点检验
public User build() {
if (name == null || password == null) {
throw new RuntimeException("用户名和密码必填");
}
if (age <= 0 || age >= 150) {
throw new RuntimeException("年龄不合法");
}
// 还可以做赋予”默认值“的功能
if (nickName == null) {
nickName = name;
}
return new User(name, password, nickName, age);
}
}
}
核心是:先把所有的属性都设置给 Builder,然后 build() 方法的时候,将这些属性复制给实际产生的对象。
看看客户端的调用:
public class APP {
public static void main(String[] args) {
User d = User.builder()
.name("foo")
.password("pAss12345")
.age(25)
.build();
}
}
说实话,建造者模式的链式写法很吸引人,但是,多写了很多“无用”的 builder 的代码,感觉这个模式没什么用。不过,当属性很多,而且有些必填,有些选填的时候,这个模式会使代码清晰很多。我们可以在 Builder 的构造方法中强制让调用者提供必填字段,还有,在 build() 方法中校验各个参数比在 User 的构造方法中校验,代码要优雅一些。
题外话,强烈建议读者使用 lombok,用了 lombok 以后,上面的一大堆代码会变成如下这样:
@Builder
class User {
private String name;
private String password;
private String nickName;
private int age;
}
怎么样,省下来的时间是不是又可以干点别的了。
当然,如果你只是想要链式写法,不想要建造者模式,有个很简单的办法,User 的 getter 方法不变,所有的 setter 方法都让其 return this 就可以了,然后就可以像下面这样调用:
User user = new User().setName("").setPassword("").setAge(20);
很多人是这么用的,但是笔者觉得其实这种写法非常地不优雅,不是很推荐使用。
原型模式
这是我要说的创建型模式的最后一个设计模式了。
原型模式很简单:有一个原型实例,基于这个原型实例产生新的实例,也就是“克隆”了。
Object 类中有一个 clone() 方法,它用于生成一个新的对象,当然,如果我们要调用这个方法,java 要求我们的类必须先实现 Cloneable 接口,此接口没有定义任何方法,但是不这么做的话,在 clone() 的时候,会抛出 CloneNotSupportedException 异常。
protected native Object clone() throws CloneNotSupportedException;
java 的克隆是浅克隆,碰到对象引用的时候,克隆出来的对象和原对象中的引用将指向同一个对象。通常实现深克隆的方法是将对象进行序列化,然后再进行反序列化。
原型模式了解到这里我觉得就够了,各种变着法子说这种代码或那种代码是原型模式,没什么意义。
创建型模式总结
创建型模式总体上比较简单,它们的作用就是为了产生实例对象,算是各种工作的第一步了,因为我们写的是面向对象的代码,所以我们第一步当然是需要创建一个对象了。
简单工厂模式最简单;工厂模式在简单工厂模式的基础上增加了选择工厂的维度,需要第一步选择合适的工厂;抽象工厂模式有产品族的概念,如果各个产品是存在兼容性问题的,就要用抽象工厂模式。
单例模式就不说了,为了保证全局使用的是同一对象,一方面是安全性考虑,一方面是为了节省资源;建造者模式专门对付属性很多的那种类,为了让代码更优美;原型模式用得最少,了解和 Object 类中的 clone() 方法相关的知识即可。
结构型模式
前面创建型模式介绍了创建对象的一些设计模式,这节介绍的结构型模式旨在通过改变代码结构来达到解耦的目的,使得我们的代码容易维护和扩展。
代理模式
第一个要介绍的代理模式是最常使用的模式之一了,用一个代理来隐藏具体实现类的实现细节,通常还用于在真实的实现的前后添加一部分逻辑。
既然说是代理,那就要对客户端隐藏真实实现,由代理来负责客户端的所有请求。当然,代理只是个代理,它不会完成实际的业务逻辑,而是一层皮而已,但是对于客户端来说,它必须表现得就是客户端需要的真实实现。
理解代理这个词,这个模式其实就简单了。
public interface FoodService {
Food makeChicken();
Food makeNoodle();
}
public class FoodServiceImpl implements FoodService {
public Food makeChicken() {
Food f = new Chicken()
f.setChicken("1kg");
f.setSpicy("1g");
f.setSalt("3g");
return f;
}
public Food makeNoodle() {
Food f = new Noodle();
f.setNoodle("500g");
f.setSalt("5g");
return f;
}
}
// 代理要表现得“就像是”真实实现类,所以需要实现 FoodService
public class FoodServiceProxy implements FoodService {
// 内部一定要有一个真实的实现类,当然也可以通过构造方法注入
private FoodService foodService = new FoodServiceImpl();
public Food makeChicken() {
System.out.println("我们马上要开始制作鸡肉了");
// 如果我们定义这句为核心代码的话,那么,核心代码是真实实现类做的,
// 代理只是在核心代码前后做些“无足轻重”的事情
Food food = foodService.makeChicken();
System.out.println("鸡肉制作完成啦,加点胡椒粉"); // 增强
food.addCondiment("pepper");
return food;
}
public Food makeNoodle() {
System.out.println("准备制作拉面~");
Food food = foodService.makeNoodle();
System.out.println("制作完成啦")
return food;
}
}
客户端调用,注意,我们要用代理来实例化接口:
// 这里用代理类来实例化
FoodService foodService = new FoodServiceProxy();
foodService.makeChicken();
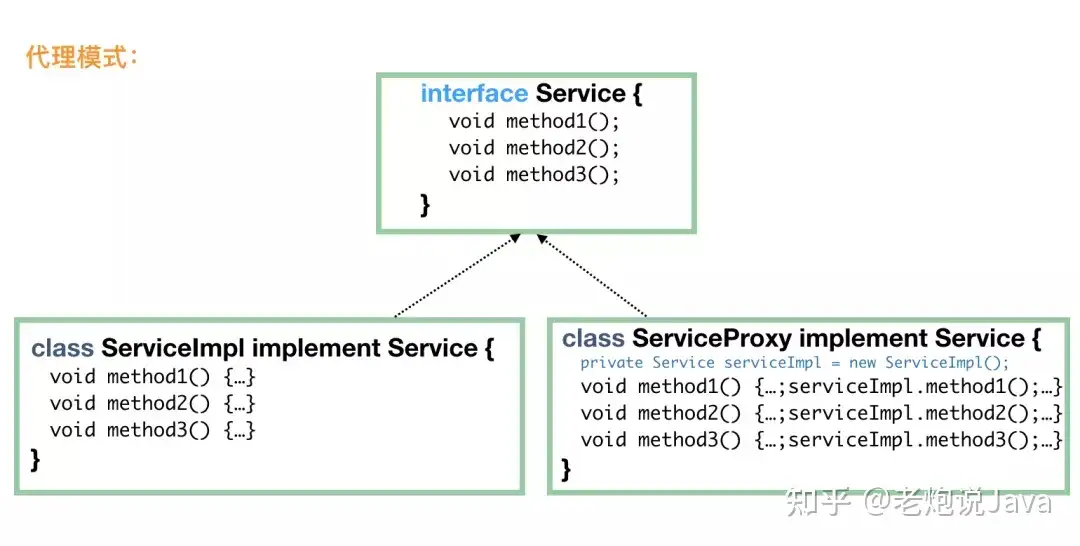
我们发现没有,代理模式说白了就是做 “方法包装” 或做 “方法增强”。在面向切面编程中,其实就是动态代理的过程。比如 Spring 中,我们自己不定义代理类,但是 Spring 会帮我们动态来定义代理,然后把我们定义在 @Before、@After、@Around 中的代码逻辑动态添加到代理中。
说到动态代理,又可以展开说,Spring 中实现动态代理有两种,一种是如果我们的类定义了接口,如 UserService 接口和 UserServiceImpl 实现,那么采用 JDK 的动态代理,感兴趣的读者可以去看看 java.lang.reflect.Proxy 类的源码;另一种是我们自己没有定义接口的,Spring 会采用 CGLIB 进行动态代理,它是一个 jar 包,性能还不错。
适配器模式
说完代理模式,说适配器模式,是因为它们很相似,这里可以做个比较。
适配器模式做的就是,有一个接口需要实现,但是我们现成的对象都不满足,需要加一层适配器来进行适配。
适配器模式总体来说分三种:默认适配器模式、对象适配器模式、类适配器模式。先不急着分清楚这几个,先看看例子再说。
默认适配器模式
首先,我们先看看最简单的适配器模式**默认适配器模式(Default Adapter)**是怎么样的。
我们用 Appache commons-io 包中的 FileAlterationListener 做例子,此接口定义了很多的方法,用于对文件或文件夹进行监控,一旦发生了对应的操作,就会触发相应的方法。
public interface FileAlterationListener {
void onStart(final FileAlterationObserver observer);
void onDirectoryCreate(final File directory);
void onDirectoryChange(final File directory);
void onDirectoryDelete(final File directory);
void onFileCreate(final File file);
void onFileChange(final File file);
void onFileDelete(final File file);
void onStop(final FileAlterationObserver observer);
}
此接口的一大问题是抽象方法太多了,如果我们要用这个接口,意味着我们要实现每一个抽象方法,如果我们只是想要监控文件夹中的文件创建和文件删除事件,可是我们还是不得不实现所有的方法,很明显,这不是我们想要的。
所以,我们需要下面的一个适配器,它用于实现上面的接口,但是所有的方法都是空方法,这样,我们就可以转而定义自己的类来继承下面这个类即可。
public class FileAlterationListenerAdaptor implements FileAlterationListener {
public void onStart(final FileAlterationObserver observer) {
}
public void onDirectoryCreate(final File directory) {
}
public void onDirectoryChange(final File directory) {
}
public void onDirectoryDelete(final File directory) {
}
public void onFileCreate(final File file) {
}
public void onFileChange(final File file) {
}
public void onFileDelete(final File file) {
}
public void onStop(final FileAlterationObserver observer) {
}
}
比如我们可以定义以下类,我们仅仅需要实现我们想实现的方法就可以了:
public class FileMonitor extends FileAlterationListenerAdaptor {
public void onFileCreate(final File file) {
// 文件创建
doSomething();
}
public void onFileDelete(final File file) {
// 文件删除
doSomething();
}
}
当然,上面说的只是适配器模式的其中一种,也是最简单的一种,无需多言。下面,再介绍 “正统的” 适配器模式。
对象适配器模式
来看一个《Head First 设计模式》中的一个例子,我稍微修改了一下,看看怎么将鸡适配成鸭,这样鸡也能当鸭来用。因为,现在鸭这个接口,我们没有合适的实现类可以用,所以需要适配器。
public interface Duck {
public void quack(); // 鸭的呱呱叫
public void fly(); // 飞
}
public interface Cock {
public void gobble(); // 鸡的咕咕叫
public void fly(); // 飞
}
public class WildCock implements Cock {
public void gobble() {
System.out.println("咕咕叫");
}
public void fly() {
System.out.println("鸡也会飞哦");
}
}
鸭接口有 fly() 和 quare() 两个方法,鸡 Cock 如果要冒充鸭,fly() 方法是现成的,但是鸡不会鸭的呱呱叫,没有 quack() 方法。这个时候就需要适配了:
// 毫无疑问,首先,这个适配器肯定需要 implements Duck,这样才能当做鸭来用
public class CockAdapter implements Duck {
Cock cock;
// 构造方法中需要一个鸡的实例,此类就是将这只鸡适配成鸭来用
public CockAdapter(Cock cock) {
this.cock = cock;
}
// 实现鸭的呱呱叫方法
@Override
public void quack() {
// 内部其实是一只鸡的咕咕叫
cock.gobble();
}
@Override
public void fly() {
cock.fly();
}
}
客户端调用很简单了:
public static void main(String[] args) {
// 有一只野鸡
Cock wildCock = new WildCock();
// 成功将野鸡适配成鸭
Duck duck = new CockAdapter(wildCock);
...
}
到这里,大家也就知道了适配器模式是怎么回事了。无非是我们需要一只鸭,但是我们只有一只鸡,这个时候就需要定义一个适配器,由这个适配器来充当鸭,但是适配器里面的方法还是由鸡来实现的。
我们用一个图来简单说明下:
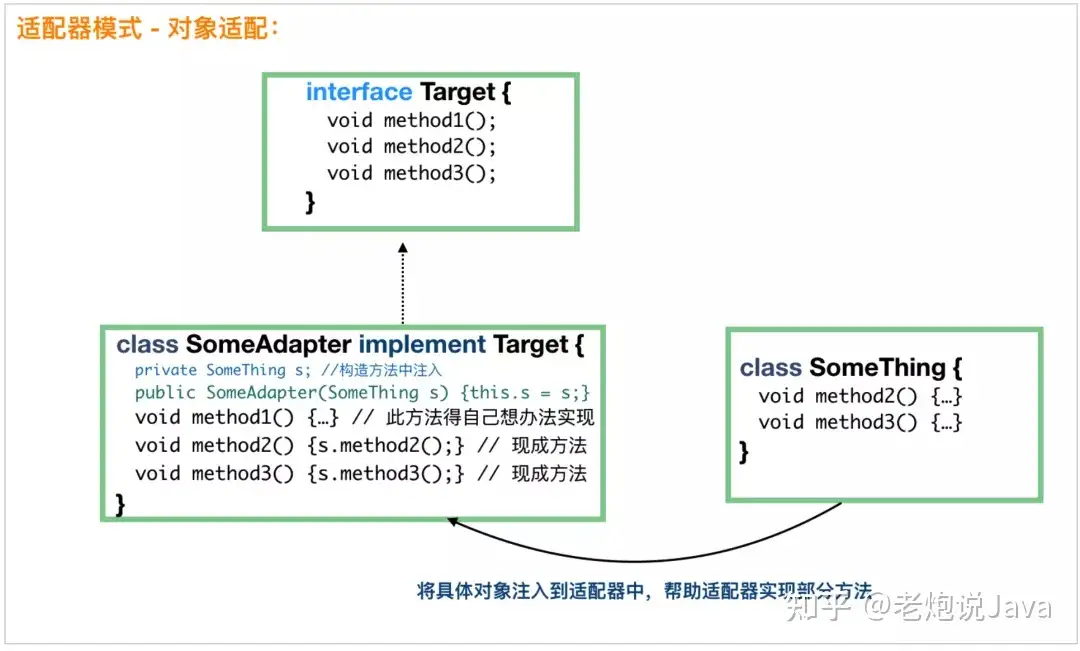
上图应该还是很容易理解的,我就不做更多的解释了。下面,我们看看类适配模式怎么样的。
类适配器模式
废话少说,直接上图:
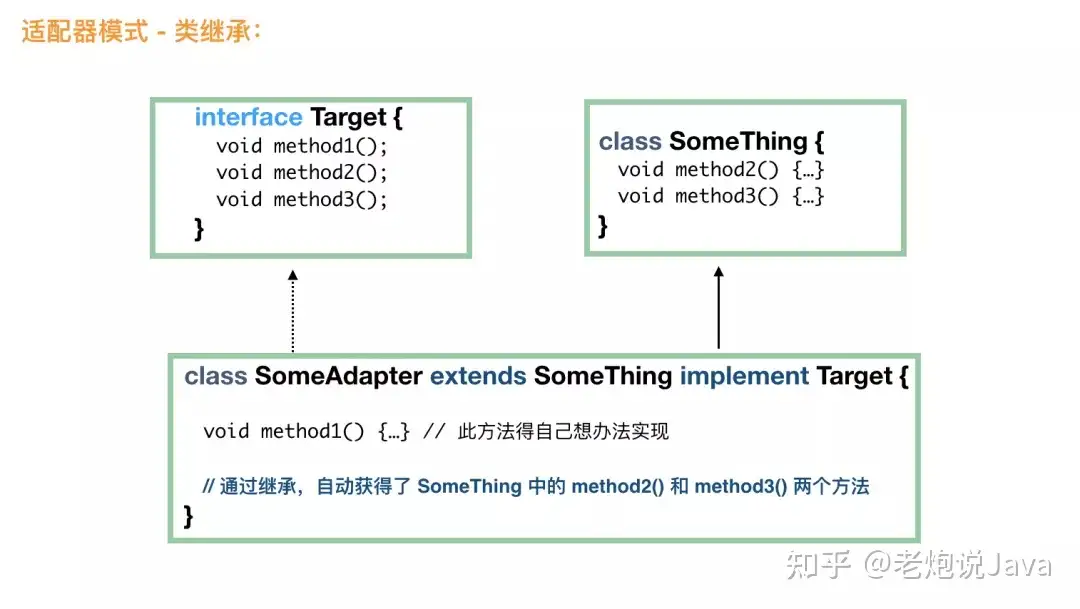
看到这个图,大家应该很容易理解的吧,通过继承的方法,适配器自动获得了所需要的大部分方法。这个时候,客户端使用更加简单,直接 Target t = new SomeAdapter(); 就可以了。
适配器模式总结
类适配和对象适配的异同
一个采用继承,一个采用组合;
类适配属于静态实现,对象适配属于组合的动态实现,对象适配需要多实例化一个对象。
总体来说,对象适配用得比较多。
适配器模式和代理模式的异同
比较这两种模式,其实是比较对象适配器模式和代理模式,在代码结构上,它们很相似,都需要一个具体的实现类的实例。但是它们的目的不一样,代理模式做的是增强原方法的活;适配器做的是适配的活,为的是提供“把鸡包装成鸭,然后当做鸭来使用”,而鸡和鸭它们之间原本没有继承关系。
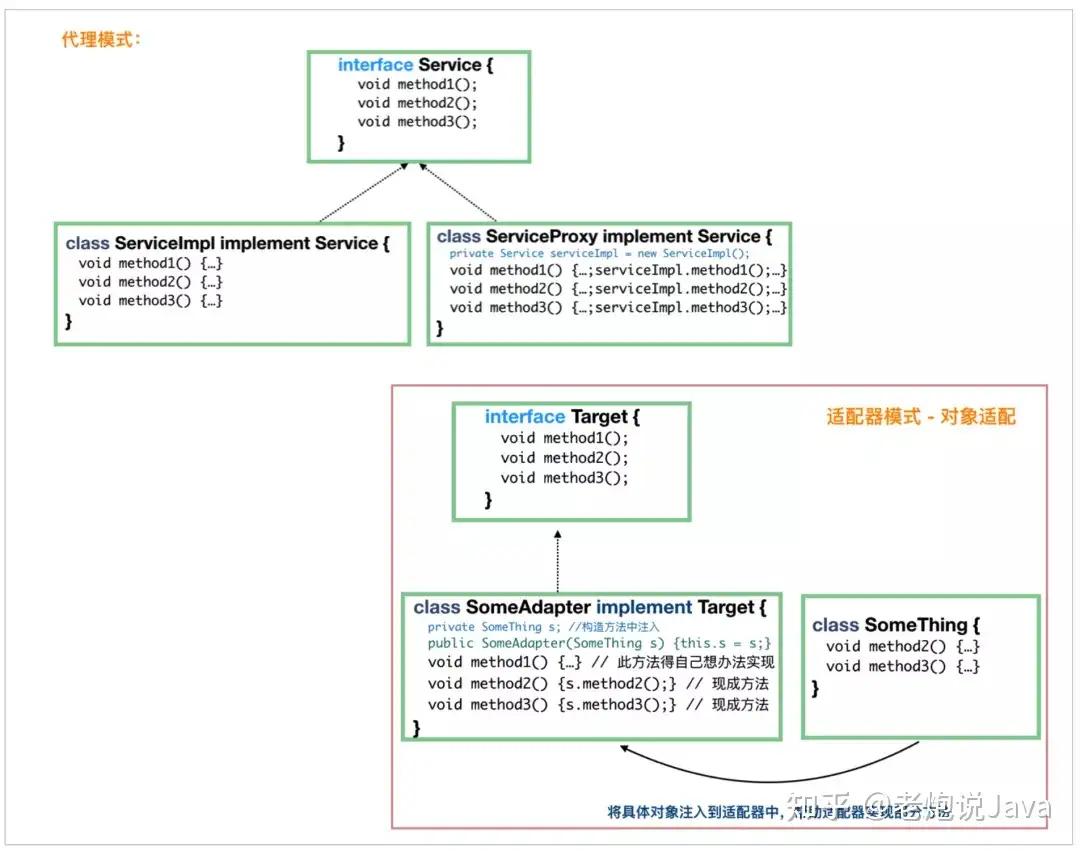
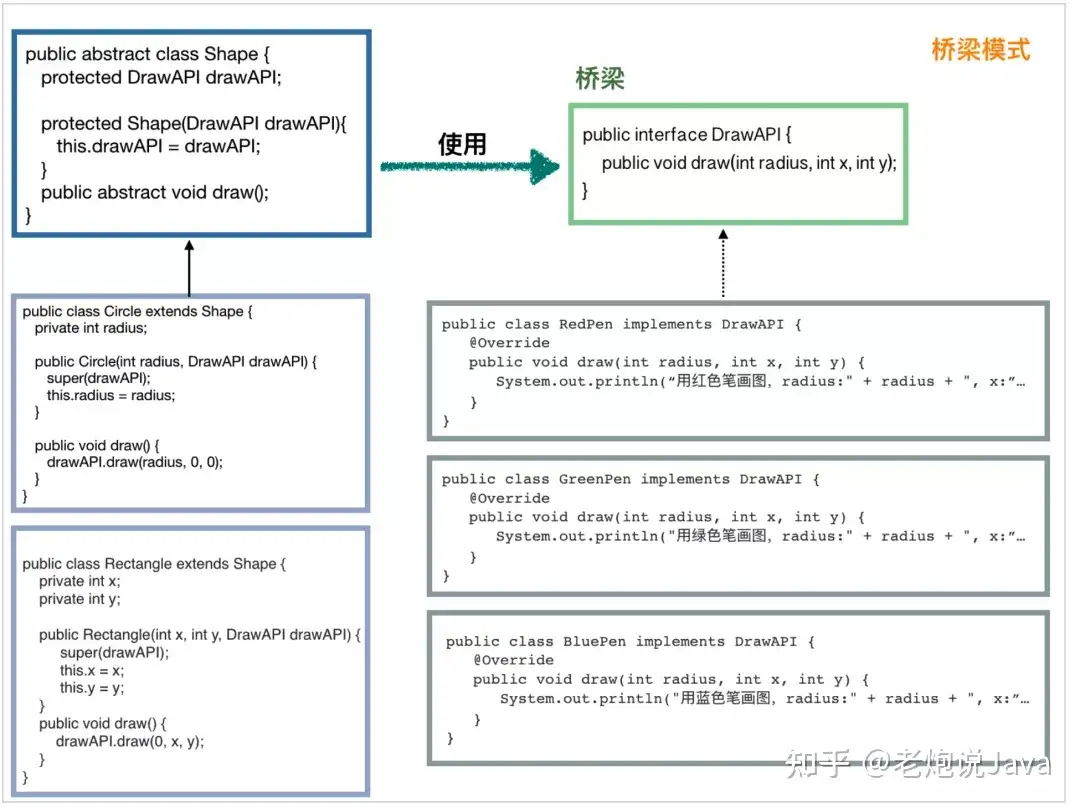
桥梁模式
理解桥梁模式,其实就是理解代码抽象和解耦。
我们首先需要一个桥梁,它是一个接口,定义提供的接口方法。
public interface DrawAPI {
public void draw(int radius, int x, int y);
}
然后是一系列实现类:
public class RedPen implements DrawAPI {
@Override
public void draw(int radius, int x, int y) {
System.out.println("用红色笔画图,radius:" + radius + ", x:" + x + ", y:" + y);
}
}
public class GreenPen implements DrawAPI {
@Override
public void draw(int radius, int x, int y) {
System.out.println("用绿色笔画图,radius:" + radius + ", x:" + x + ", y:" + y);
}
}
public class BluePen implements DrawAPI {
@Override
public void draw(int radius, int x, int y) {
System.out.println("用蓝色笔画图,radius:" + radius + ", x:" + x + ", y:" + y);
}
}
定义一个抽象类,此类的实现类都需要使用 DrawAPI:
public abstract class Shape {
protected DrawAPI drawAPI;
protected Shape(DrawAPI drawAPI) {
this.drawAPI = drawAPI;
}
public abstract void draw();
}
定义抽象类的子类:
// 圆形
public class Circle extends Shape {
private int radius;
public Circle(int radius, DrawAPI drawAPI) {
super(drawAPI);
this.radius = radius;
}
public void draw() {
drawAPI.draw(radius, 0, 0);
}
}
// 长方形
public class Rectangle extends Shape {
private int x;
private int y;
public Rectangle(int x, int y, DrawAPI drawAPI) {
super(drawAPI);
this.x = x;
this.y = y;
}
public void draw() {
drawAPI.draw(0, x, y);
}
}
最后,我们来看客户端演示:
public static void main(String[] args) {
Shape greenCircle = new Circle(10, new GreenPen());
Shape redRectangle = new Rectangle(4, 8, new RedPen());
greenCircle.draw();
redRectangle.draw();
}
可能大家看上面一步步还不是特别清晰,我把所有的东西整合到一张图上:
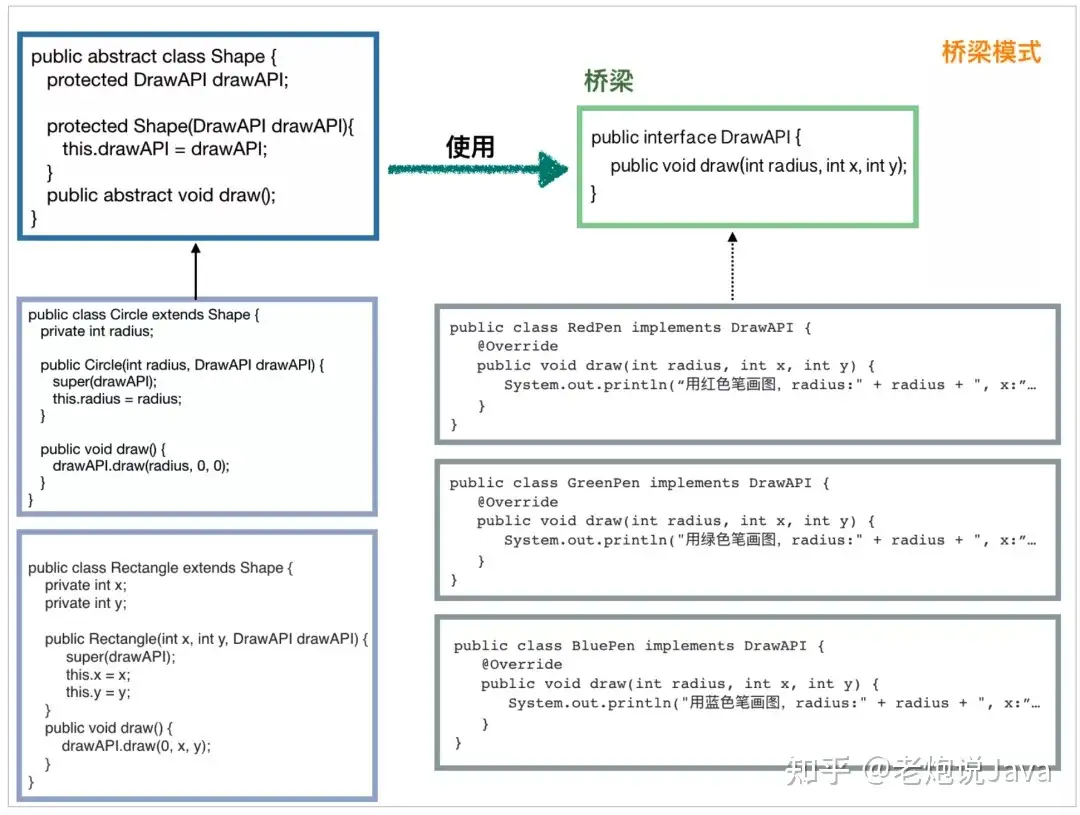
这回大家应该就知道抽象在哪里,怎么解耦了吧。桥梁模式的优点也是显而易见的,就是非常容易进行扩展。
本节引用了这里的例子,并对其进行了修改。
装饰模式
要把装饰模式说清楚明白,不是件容易的事情。也许读者知道 Java IO 中的几个类是典型的装饰模式的应用,但是读者不一定清楚其中的关系,也许看完就忘了,希望看完这节后,读者可以对其有更深的感悟。
首先,我们先看一个简单的图,看这个图的时候,了解下层次结构就可以了:
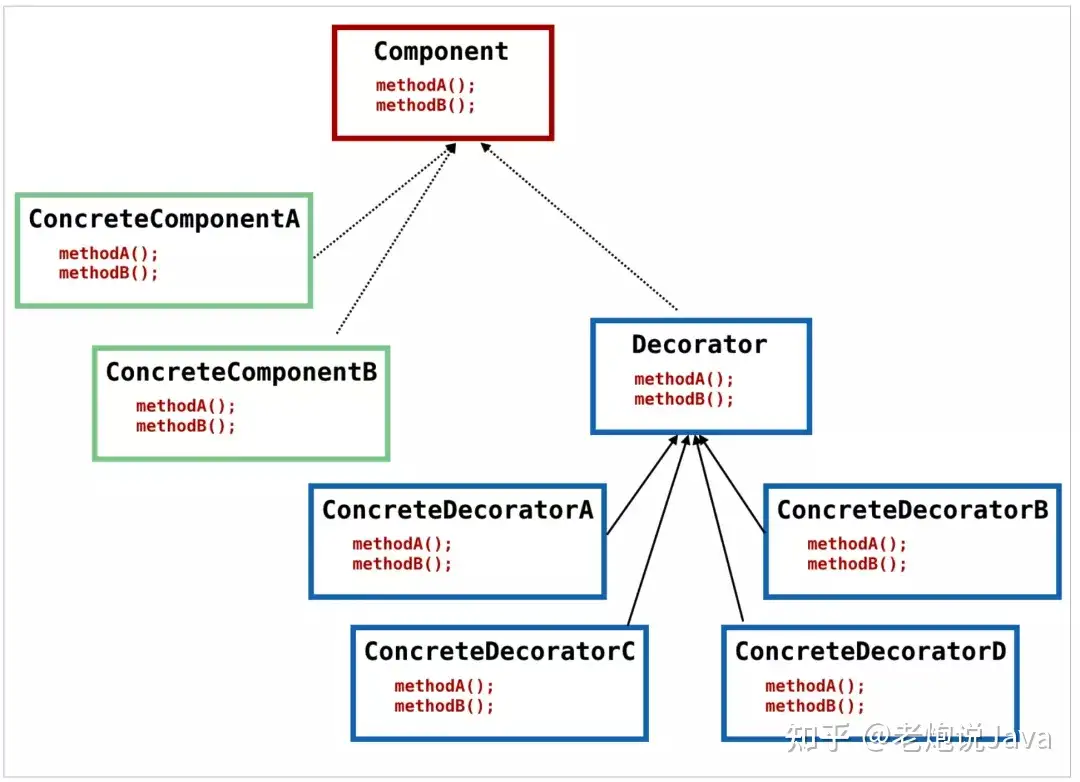
我们来说说装饰模式的出发点,从图中可以看到,接口 Component 其实已经有了 ConcreteComponentA 和 ConcreteComponentB 两个实现类了,但是,如果我们要增强这两个实现类的话,我们就可以采用装饰模式,用具体的装饰器来装饰实现类,以达到增强的目的。
从名字来简单解释下装饰器。既然说是装饰,那么往往就是添加小功能这种,而且,我们要满足可以添加多个小功能。最简单的,代理模式就可以实现功能的增强,但是代理不容易实现多个功能的增强,当然你可以说用代理包装代理的多层包装方式,但是那样的话代码就复杂了。
首先明白一些简单的概念,从图中我们看到,所有的具体装饰者们 ConcreteDecorator* 都可以作为 Component 来使用,因为它们都实现了 Component 中的所有接口。它们和 Component 实现类 ConcreteComponent* 的区别是,它们只是装饰者,起装饰作用,也就是即使它们看上去牛逼轰轰,但是它们都只是在具体的实现中加了层皮来装饰而已。
注意这段话中混杂在各个名词中的 Component 和 Decorator,别搞混了。
下面来看看一个例子,先把装饰模式弄清楚,然后再介绍下 java io 中的装饰模式的应用。
最近大街上流行起来了“快乐柠檬”,我们把快乐柠檬的饮料分为三类:红茶、绿茶、咖啡,在这三大类的基础上,又增加了许多的口味,什么金桔柠檬红茶、金桔柠檬珍珠绿茶、芒果红茶、芒果绿茶、芒果珍珠红茶、烤珍珠红茶、烤珍珠芒果绿茶、椰香胚芽咖啡、焦糖可可咖啡等等,每家店都有很长的菜单,但是仔细看下,其实原料也没几样,但是可以搭配出很多组合,如果顾客需要,很多没出现在菜单中的饮料他们也是可以做的。
在这个例子中,红茶、绿茶、咖啡是最基础的饮料,其他的像金桔柠檬、芒果、珍珠、椰果、焦糖等都属于装饰用的。当然,在开发中,我们确实可以像门店一样,开发这些类:LemonBlackTea、LemonGreenTea、MangoBlackTea、MangoLemonGreenTea……但是,很快我们就发现,这样子干肯定是不行的,这会导致我们需要组合出所有的可能,而且如果客人需要在红茶中加双份柠檬怎么办?三份柠檬怎么办?
不说废话了,上代码。
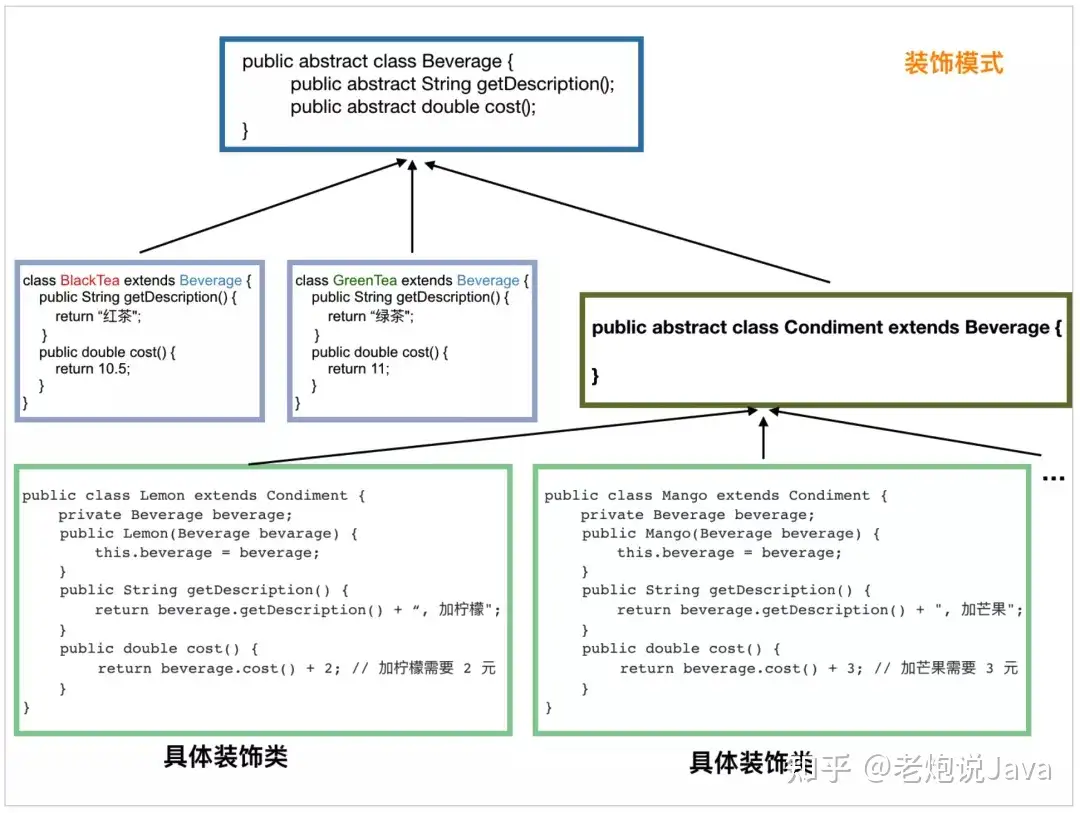
首先,定义饮料抽象基类:
public abstract class Beverage {
// 返回描述
public abstract String getDescription();
// 返回价格
public abstract double cost();
}
然后是三个基础饮料实现类,红茶、绿茶和咖啡:
public class BlackTea extends Beverage {
public String getDescription() {
return "红茶";
}
public double cost() {
return 10;
}
}
public class GreenTea extends Beverage {
public String getDescription() {
return "绿茶";
}
public double cost() {
return 11;
}
}
...// 咖啡省略
定义调料,也就是装饰者的基类,此类必须继承自 Beverage:
// 调料
public abstract class Condiment extends Beverage {
}
然后我们来定义柠檬、芒果等具体的调料,它们属于装饰者,毫无疑问,这些调料肯定都需要继承调料 Condiment 类:
public class Lemon extends Condiment {
private Beverage bevarage;
// 这里很关键,需要传入具体的饮料,如需要传入没有被装饰的红茶或绿茶,
// 当然也可以传入已经装饰好的芒果绿茶,这样可以做芒果柠檬绿茶
public Lemon(Beverage bevarage) {
this.bevarage = bevarage;
}
public String getDescription() {
// 装饰
return bevarage.getDescription() + ", 加柠檬";
}
public double cost() {
// 装饰
return beverage.cost() + 2; // 加柠檬需要 2 元
}
}
public class Mango extends Condiment {
private Beverage bevarage;
public Mango(Beverage bevarage) {
this.bevarage = bevarage;
}
public String getDescription() {
return bevarage.getDescription() + ", 加芒果";
}
public double cost() {
return beverage.cost() + 3; // 加芒果需要 3 元
}
}
...// 给每一种调料都加一个类
看客户端调用:
public static void main(String[] args) {
// 首先,我们需要一个基础饮料,红茶、绿茶或咖啡
Beverage beverage = new GreenTea();
// 开始装饰
beverage = new Lemon(beverage); // 先加一份柠檬
beverage = new Mongo(beverage); // 再加一份芒果
System.out.println(beverage.getDescription() + " 价格:¥" + beverage.cost());
//"绿茶, 加柠檬, 加芒果 价格:¥16"
}
如果我们需要 芒果-珍珠-双份柠檬-红茶:
Beverage beverage = new Mongo(new Pearl(new Lemon(new Lemon(new BlackTea()))));
是不是很变态?
看看下图可能会清晰一些:
到这里,大家应该已经清楚装饰模式了吧。
下面,我们再来说说 java IO 中的装饰模式。看下图 InputStream 派生出来的部分类:
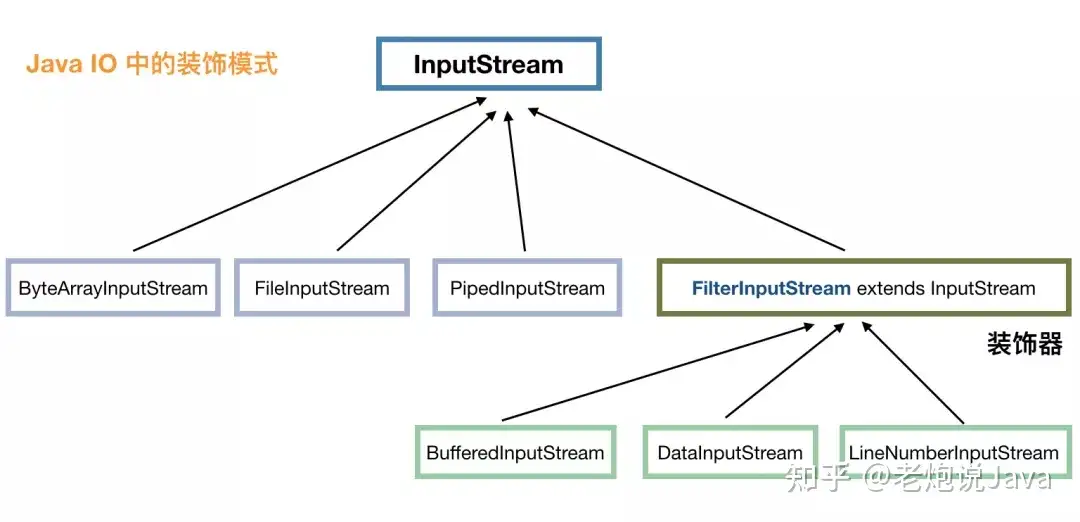
我们知道 InputStream 代表了输入流,具体的输入来源可以是文件(FileInputStream)、管道(PipedInputStream)、数组(ByteArrayInputStream)等,这些就像前面奶茶的例子中的红茶、绿茶,属于基础输入流。
FilterInputStream 承接了装饰模式的关键节点,它的实现类是一系列装饰器,比如 BufferedInputStream 代表用缓冲来装饰,也就使得输入流具有了缓冲的功能,LineNumberInputStream 代表用行号来装饰,在操作的时候就可以取得行号了,DataInputStream 的装饰,使得我们可以从输入流转换为 java 中的基本类型值。
当然,在 java IO 中,如果我们使用装饰器的话,就不太适合面向接口编程了,如:
InputStream inputStream = new LineNumberInputStream(new BufferedInputStream(new FileInputStream("")));
这样的结果是,InputStream 还是不具有读取行号的功能,因为读取行号的方法定义在 LineNumberInputStream 类中。
我们应该像下面这样使用:
DataInputStream is = new DataInputStream(
new BufferedInputStream(
new FileInputStream("")));
所以说嘛,要找到纯的严格符合设计模式的代码还是比较难的。
门面模式
门面模式(也叫外观模式,Facade Pattern)在许多源码中有使用,比如 slf4j 就可以理解为是门面模式的应用。这是一个简单的设计模式,我们直接上代码再说吧。
首先,我们定义一个接口:
public interface Shape {
void draw();
}
定义几个实现类:
public class Circle implements Shape {
@Override
public void draw() {
System.out.println("Circle::draw()");
}
}
public class Rectangle implements Shape {
@Override
public void draw() {
System.out.println("Rectangle::draw()");
}
}
客户端调用:
public static void main(String[] args) {
// 画一个圆形
Shape circle = new Circle();
circle.draw();
// 画一个长方形
Shape rectangle = new Rectangle();
rectangle.draw();
}
以上是我们常写的代码,我们需要画圆就要先实例化圆,画长方形就需要先实例化一个长方形,然后再调用相应的 draw() 方法。
下面,我们看看怎么用门面模式来让客户端调用更加友好一些。
我们先定义一个门面:
public class ShapeMaker {
private Shape circle;
private Shape rectangle;
private Shape square;
public ShapeMaker() {
circle = new Circle();
rectangle = new Rectangle();
square = new Square();
}
/**
* 下面定义一堆方法,具体应该调用什么方法,由这个门面来决定
*/
public void drawCircle(){
circle.draw();
}
public void drawRectangle(){
rectangle.draw();
}
public void drawSquare(){
square.draw();
}
}
看看现在客户端怎么调用:
public static void main(String[] args) {
ShapeMaker shapeMaker = new ShapeMaker();
// 客户端调用现在更加清晰了
shapeMaker.drawCircle();
shapeMaker.drawRectangle();
shapeMaker.drawSquare();
}
门面模式的优点显而易见,客户端不再需要关注实例化时应该使用哪个实现类,直接调用门面提供的方法就可以了,因为门面类提供的方法的方法名对于客户端来说已经很友好了。
组合模式
组合模式用于表示具有层次结构的数据,使得我们对单个对象和组合对象的访问具有一致性。
直接看一个例子吧,每个员工都有姓名、部门、薪水这些属性,同时还有下属员工集合(虽然可能集合为空),而下属员工和自己的结构是一样的,也有姓名、部门这些属性,同时也有他们的下属员工集合。
public class Employee {
private String name;
private String dept;
private int salary;
private List<Employee> subordinates; // 下属
public Employee(String name,String dept, int sal) {
this.name = name;
this.dept = dept;
this.salary = sal;
subordinates = new ArrayList<Employee>();
}
public void add(Employee e) {
subordinates.add(e);
}
public void remove(Employee e) {
subordinates.remove(e);
}
public List<Employee> getSubordinates(){
return subordinates;
}
public String toString(){
return ("Employee :[ Name : " + name + ", dept : " + dept + ", salary :" + salary+" ]");
}
}
通常,这种类需要定义 add(node)、remove(node)、getChildren() 这些方法。
这说的其实就是组合模式,这种简单的模式我就不做过多介绍了,相信各位读者也不喜欢看我写废话。
享元模式
英文是 Flyweight Pattern,不知道是谁最先翻译的这个词,感觉这翻译真的不好理解,我们试着强行关联起来吧。Flyweight 是轻量级的意思,享元分开来说就是 共享 元器件,也就是复用已经生成的对象,这种做法当然也就是轻量级的了。
复用对象最简单的方式是,用一个 HashMap 来存放每次新生成的对象。每次需要一个对象的时候,先到 HashMap 中看看有没有,如果没有,再生成新的对象,然后将这个对象放入 HashMap 中。
这种简单的代码我就不演示了。
结构型模式总结
前面,我们说了代理模式、适配器模式、桥梁模式、装饰模式、门面模式、组合模式和享元模式。读者是否可以分别把这几个模式说清楚了呢?在说到这些模式的时候,心中是否有一个清晰的图或处理流程在脑海里呢?
代理模式是做方法增强的,适配器模式是把鸡包装成鸭这种用来适配接口的,桥梁模式做到了很好的解耦,装饰模式从名字上就看得出来,适合于装饰类或者说是增强类的场景,门面模式的优点是客户端不需要关心实例化过程,只要调用需要的方法即可,组合模式用于描述具有层次结构的数据,享元模式是为了在特定的场景中缓存已经创建的对象,用于提高性能。
行为型模式
行为型模式关注的是各个类之间的相互作用,将职责划分清楚,使得我们的代码更加地清晰。
策略模式
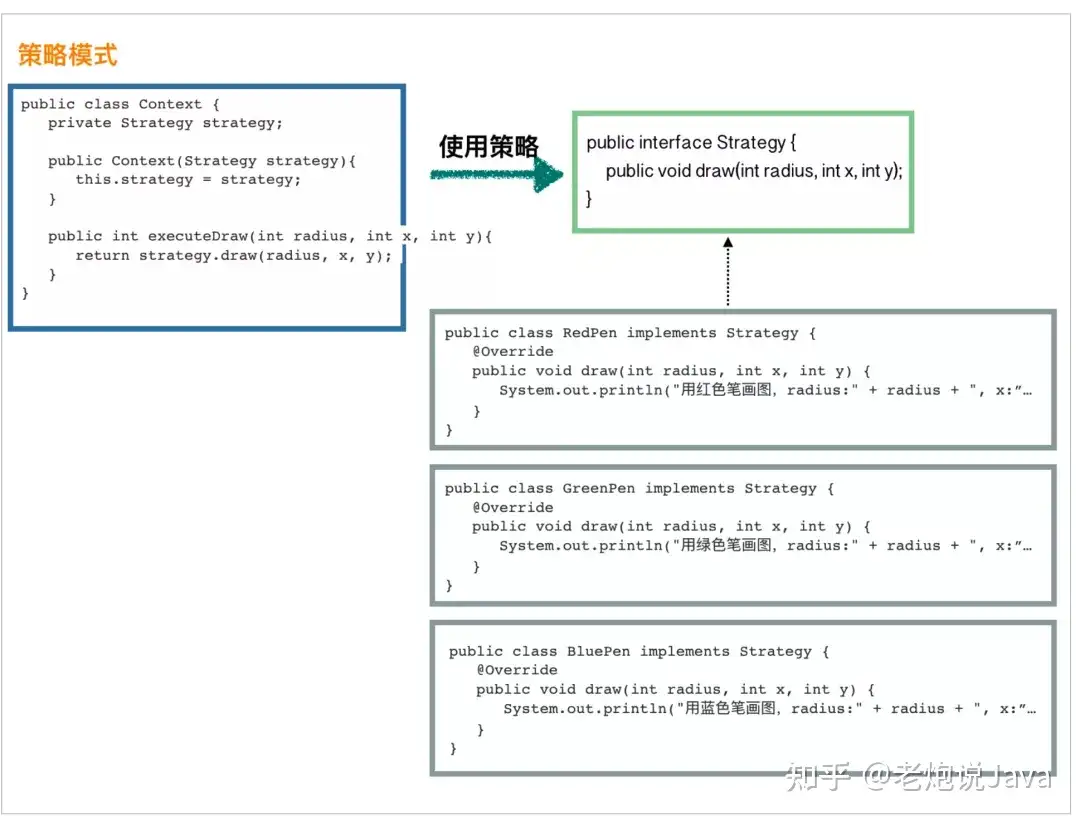
策略模式太常用了,所以把它放到最前面进行介绍。它比较简单,我就不废话,直接用代码说事吧。
下面设计的场景是,我们需要画一个图形,可选的策略就是用红色笔来画,还是绿色笔来画,或者蓝色笔来画。
首先,先定义一个策略接口:
public interface Strategy {
public void draw(int radius, int x, int y);
}
然后我们定义具体的几个策略:
public class RedPen implements Strategy {
@Override
public void draw(int radius, int x, int y) {
System.out.println("用红色笔画图,radius:" + radius + ", x:" + x + ", y:" + y);
}
}
public class GreenPen implements Strategy {
@Override
public void draw(int radius, int x, int y) {
System.out.println("用绿色笔画图,radius:" + radius + ", x:" + x + ", y:" + y);
}
}
public class BluePen implements Strategy {
@Override
public void draw(int radius, int x, int y) {
System.out.println("用蓝色笔画图,radius:" + radius + ", x:" + x + ", y:" + y);
}
}
使用策略的类:
public class Context {
private Strategy strategy;
public Context(Strategy strategy){
this.strategy = strategy;
}
public int executeDraw(int radius, int x, int y){
return strategy.draw(radius, x, y);
}
}
客户端演示:
public static void main(String[] args) {
Context context = new Context(new BluePen()); // 使用绿色笔来画
context.executeDraw(10, 0, 0);
}
放到一张图上,让大家看得清晰些:
这个时候,大家有没有联想到结构型模式中的桥梁模式,它们其实非常相似,我把桥梁模式的图拿过来大家对比下:
要我说的话,它们非常相似,桥梁模式在左侧加了一层抽象而已。桥梁模式的耦合更低,结构更复杂一些。
观察者模式
观察者模式对于我们来说,真是再简单不过了。无外乎两个操作,观察者订阅自己关心的主题和主题有数据变化后通知观察者们。
首先,需要定义主题,每个主题需要持有观察者列表的引用,用于在数据变更的时候通知各个观察者:
public class Subject {
private List<Observer> observers = new ArrayList<Observer>();
private int state;
public int getState() {
return state;
}
public void setState(int state) {
this.state = state;
// 数据已变更,通知观察者们
notifyAllObservers();
}
// 注册观察者
public void attach(Observer observer) {
observers.add(observer);
}
// 通知观察者们
public void notifyAllObservers() {
for (Observer observer : observers) {
observer.update();
}
}
}
定义观察者接口:
public abstract class Observer {
protected Subject subject;
public abstract void update();
}
其实如果只有一个观察者类的话,接口都不用定义了,不过,通常场景下,既然用到了观察者模式,我们就是希望一个事件出来了,会有多个不同的类需要处理相应的信息。比如,订单修改成功事件,我们希望发短信的类得到通知、发邮件的类得到通知、处理物流信息的类得到通知等。
我们来定义具体的几个观察者类:
public class BinaryObserver extends Observer {
// 在构造方法中进行订阅主题
public BinaryObserver(Subject subject) {
this.subject = subject;
// 通常在构造方法中将 this 发布出去的操作一定要小心
this.subject.attach(this);
}
// 该方法由主题类在数据变更的时候进行调用
@Override
public void update() {
String result = Integer.toBinaryString(subject.getState());
System.out.println("订阅的数据发生变化,新的数据处理为二进制值为:" + result);
}
}
public class HexaObserver extends Observer {
public HexaObserver(Subject subject) {
this.subject = subject;
this.subject.attach(this);
}
@Override
public void update() {
String result = Integer.toHexString(subject.getState()).toUpperCase();
System.out.println("订阅的数据发生变化,新的数据处理为十六进制值为:" + result);
}
}
客户端使用也非常简单:
public static void main(String[] args) {
// 先定义一个主题
Subject subject1 = new Subject();
// 定义观察者
new BinaryObserver(subject1);
new HexaObserver(subject1);
// 模拟数据变更,这个时候,观察者们的 update 方法将会被调用
subject.setState(11);
}
output:
订阅的数据发生变化,新的数据处理为二进制值为:1011
订阅的数据发生变化,新的数据处理为十六进制值为:B
当然,jdk 也提供了相似的支持,具体的大家可以参考 java.util.Observable 和 java.util.Observer 这两个类。
实际生产过程中,观察者模式往往用消息中间件来实现,如果要实现单机观察者模式,笔者建议读者使用 Guava 中的 EventBus,它有同步实现也有异步实现,本文主要介绍设计模式,就不展开说了。
还有,即使是上面的这个代码,也会有很多变种,大家只要记住核心的部分,那就是一定有一个地方存放了所有的观察者,然后在事件发生的时候,遍历观察者,调用它们的回调函数。
责任链模式
责任链通常需要先建立一个单向链表,然后调用方只需要调用头部节点就可以了,后面会自动流转下去。比如流程审批就是一个很好的例子,只要终端用户提交申请,根据申请的内容信息,自动建立一条责任链,然后就可以开始流转了。
有这么一个场景,用户参加一个活动可以领取奖品,但是活动需要进行很多的规则校验然后才能放行,比如首先需要校验用户是否是新用户、今日参与人数是否有限额、全场参与人数是否有限额等等。设定的规则都通过后,才能让用户领走奖品。
如果产品给你这个需求的话,我想大部分人一开始肯定想的就是,用一个 List 来存放所有的规则,然后 foreach 执行一下每个规则就好了。不过,读者也先别急,看看责任链模式和我们说的这个有什么不一样?
首先,我们要定义流程上节点的基类:
public abstract class RuleHandler {
// 后继节点
protected RuleHandler successor;
public abstract void apply(Context context);
public void setSuccessor(RuleHandler successor) {
this.successor = successor;
}
public RuleHandler getSuccessor() {
return successor;
}
}
接下来,我们需要定义具体的每个节点了。
校验用户是否是新用户:
public class NewUserRuleHandler extends RuleHandler {
public void apply(Context context) {
if (context.isNewUser()) {
// 如果有后继节点的话,传递下去
if (this.getSuccessor() != null) {
this.getSuccessor().apply(context);
}
} else {
throw new RuntimeException("该活动仅限新用户参与");
}
}
}
校验用户所在地区是否可以参与:
public class LocationRuleHandler extends RuleHandler {
public void apply(Context context) {
boolean allowed = activityService.isSupportedLocation(context.getLocation);
if (allowed) {
if (this.getSuccessor() != null) {
this.getSuccessor().apply(context);
}
} else {
throw new RuntimeException("非常抱歉,您所在的地区无法参与本次活动");
}
}
}
校验奖品是否已领完:
public class LimitRuleHandler extends RuleHandler {
public void apply(Context context) {
int remainedTimes = activityService.queryRemainedTimes(context); // 查询剩余奖品
if (remainedTimes > 0) {
if (this.getSuccessor() != null) {
this.getSuccessor().apply(userInfo);
}
} else {
throw new RuntimeException("您来得太晚了,奖品被领完了");
}
}
}
客户端:
public static void main(String[] args) {
RuleHandler newUserHandler = new NewUserRuleHandler();
RuleHandler locationHandler = new LocationRuleHandler();
RuleHandler limitHandler = new LimitRuleHandler();
// 假设本次活动仅校验地区和奖品数量,不校验新老用户
locationHandler.setSuccessor(limitHandler);
locationHandler.apply(context);
}
代码其实很简单,就是先定义好一个链表,然后在通过任意一节点后,如果此节点有后继节点,那么传递下去。
至于它和我们前面说的用一个 List 存放需要执行的规则的做法有什么异同,留给读者自己琢磨吧。
模板方法模式
在含有继承结构的代码中,模板方法模式是非常常用的。
通常会有一个抽象类:
public abstract class AbstractTemplate {
// 这就是模板方法
public void templateMethod() {
init();
apply(); // 这个是重点
end(); // 可以作为钩子方法
}
protected void init() {
System.out.println("init 抽象层已经实现,子类也可以选择覆写");
}
// 留给子类实现
protected abstract void apply();
protected void end() {
}
}
模板方法中调用了 3 个方法,其中 apply() 是抽象方法,子类必须实现它,其实模板方法中有几个抽象方法完全是自由的,我们也可以将三个方法都设置为抽象方法,让子类来实现。也就是说,模板方法只负责定义第一步应该要做什么,第二步应该做什么,第三步应该做什么,至于怎么做,由子类来实现。
我们写一个实现类:
public class ConcreteTemplate extends AbstractTemplate {
public void apply() {
System.out.println("子类实现抽象方法 apply");
}
public void end() {
System.out.println("我们可以把 method3 当做钩子方法来使用,需要的时候覆写就可以了");
}
}
客户端调用演示:
public static void main(String[] args) {
AbstractTemplate t = new ConcreteTemplate();
// 调用模板方法
t.templateMethod();
}
代码其实很简单,基本上看到就懂了,关键是要学会用到自己的代码中。
状态模式
废话我就不说了,我们说一个简单的例子。商品库存中心有个最基本的需求是减库存和补库存,我们看看怎么用状态模式来写。
核心在于,我们的关注点不再是 Context 是该进行哪种操作,而是关注在这个 Context 会有哪些操作。
定义状态接口:
public interface State {
public void doAction(Context context);
}
定义减库存的状态:
public class DeductState implements State {
public void doAction(Context context) {
System.out.println("商品卖出,准备减库存");
context.setState(this);
//... 执行减库存的具体操作
}
public String toString() {
return "Deduct State";
}
}
定义补库存状态:
public class RevertState implements State {
public void doAction(Context context) {
System.out.println("给此商品补库存");
context.setState(this);
//... 执行加库存的具体操作
}
public String toString() {
return "Revert State";
}
}
前面用到了 context.setState(this),我们来看看怎么定义 Context 类:
public class Context {
private State state;
private String name;
public Context(String name) {
this.name = name;
}
public void setState(State state) {
this.state = state;
}
public void getState() {
return this.state;
}
}
我们来看下客户端调用,大家就一清二楚了:
public static void main(String[] args) {
// 我们需要操作的是 iPhone X
Context context = new Context("iPhone X");
// 看看怎么进行补库存操作
State revertState = new RevertState();
revertState.doAction(context);
// 同样的,减库存操作也非常简单
State deductState = new DeductState();
deductState.doAction(context);
// 如果需要我们可以获取当前的状态
// context.getState().toString();
}
读者可能会发现,在上面这个例子中,如果我们不关心当前 context 处于什么状态,那么 Context 就可以不用维护 state 属性了,那样代码会简单很多。
不过,商品库存这个例子毕竟只是个例,我们还有很多实例是需要知道当前 context 处于什么状态的。
观察者模式经典示例
简介
观察者模式 : 定义了 对象之间 一对多 的 依赖 , 令 多个 观察者 对象 同时 监听 某一个 主题对象 , 当 主题对象 发生改变时 , 所有的 观察者 都会 收到通知 并更新 ;
观察者 有多个 , 被观察的 主题对象 只有一个 ;
如 : 在购物网站 , 多个用户关注某商品后 , 当商品降价时 , 就会自动通知关注该商品的用户 ;
主题对象 : 商品是主题对象 ;
观察者 : 用户是观察者 ;
观察者注册 : 用户关注 , 相当于注册观察者 ;
通知触发条件 : 商品降价 ;
观察者模式适用场景
观察者模式适用场景 : 关联行为 场景 , 建立一套 触发机制 ;
如 : 用户关注某个商品的价格 , 降价时进行通知 , 这样 用户 和 商品 产生了关联 , 触发机制就是 商品降价 ,
如:游戏设计中,人物的上下左右移动,不同的事件通过使用观察者模式来进行响应
如:也可在消息接收和解析中使用,如现在有一个接收器负责接收云端指令,收到云端指令后要进行解析,如果我们把解析指令这个操作编写成指令解析器的形式,这样后续新增指令或改变指令形式会继续修改指令解析器,违背了开闭原则,这个时候我们可以用观察者模式来进行处理
观察者模式优缺点
观察者模式 优点 :
抽象耦合 : 在 观察者 和 被观察者 之间 , 建立了一个 抽象的 耦合 ; 由于 耦合 是抽象的 , 可以很容易 扩展 观察者 和 被观察者 ;
广播通信 : 观察者模式 支持 广播通信 , 类似于消息广播 , 如果需要接收消息 , 只需要注册一下即可 ;
观察者模式 缺点 :
依赖过多 : 观察者 之间 细节依赖 过多 , 会增加 时间消耗 和 程序的复杂程度 ;
这里的 细节依赖 指的是 触发机制 , 触发链条 ; 如果 观察者设置过多 , 每次触发都要花很长时间去处理通知 ;
循环调用 : 避免 循环调用 , 观察者 与 被观察者 之间 绝对不允许循环依赖 , 否则会触发 二者 之间的循环调用 , 导致系统崩溃 ;
观察者模式基本实例
JDK 中提供了观察者模式的支持 ;
被观察者 : 被观察者 继承 Observable 类 ;
观察者 : 观察者 实现 Observer 接口 ;
关联 观察者 与 被观察者 : 调用 被观察者 的 addObserver 方法 , 关联二者 ;
触发通知 : 被观察者 数据改变时 , 调用 setChanged 和 notifyObservers 方法 , 会自动回调 观察者的 update 方法 ;
用户在游戏中提出问题 , 管理员负责监听并处理问题 ;
1、被观察者
package observer;
import java.util.Observable;
/**
* 被观察的主题对象
* JDK 提供了对观察者模式的支持 , 被观察者可以继承 Observable 类
*
* 被观察对象 继承 Observable 类
*/
public class Game extends Observable {
private String name;
public Game(String name) {
this.name = name;
}
public String getName() {
return name;
}
/**
* 用户提交问题
* @param game
* @param question
*/
public void produceQuestion(Game game, Question question) {
System.out.println(question.getUserName() +
" 在 " + game.name + " 游戏中提交问题 : " + question.getContent());
// 该方法是 Observable 提供的方法
// 将 private boolean changed = false 成员变量设置为 true
// 代表 被观察者 的状态发生了改变
setChanged();
// 通知 观察者
notifyObservers(question);
}
}
2、观察者
package observer;
import java.util.Observable;
import java.util.Observer;
/**
* 管理员类
* 管理员类观察的是游戏
* 用户反馈的问题 属于 游戏 , 管理员关注的是游戏
* 无法关注 问题
*
* 如 : 在电商平台 , 关注的是某个商品 , 在降价时发送通知
* 商品是存在的 , 降价消息 在关注的时候还没有被创建 , 是无法获取依赖的
*/
public class Manager implements Observer {
/**
* 管理员名称
*/
private String name;
public Manager(String name) {
this.name = name;
}
@Override
public void update(Observable o, Object arg) {
// 获取 被观察者 对象
Game game = (Game) o;
// 获取 被观察者 对象 调用 notifyObservers 方法的参数
Question question = (Question) arg;
System.out.println(name + " 观察者 接收到 被观察者 " + game.getName() +
" 的通知 , 用户 " + question.getUserName() +
" 提出问题 " + question.getContent());
}
}3、通知类
package observer;
public class Question {
/**
* 用户名
*/
private String userName;
/**
* 问题内容
*/
private String content;
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}4、测试类
package observer;
public class Main {
public static void main(String[] args) {
// 创建被观察者
Game game = new Game("Cat And Mouse");
// 创建观察者
Manager manager = new Manager("Tom");
// 关联 观察者 与 被观察者
game.addObserver(manager);
// 业务逻辑 : 用户提出问题到游戏中 , 管理员接收到通知消息
Question question = new Question();
question.setUserName("Jerry");
question.setContent("游戏崩溃");
// 在游戏中提交问题
game.produceQuestion(game, question);
}
}
执行结果:
Jerry 在 Cat And Mouse 游戏中提交问题 : 游戏崩溃
Tom 观察者 接收到 被观察者 Cat And Mouse 的通知 , 用户 Jerry 提出问题 游戏崩溃总结
设计模式是一套可复用的解决方案,用于应对软件开发中的常见问题。它们并不是具体的代码,而是经过验证的设计和架构方法,旨在提升代码的结构、可维护性和可读性。
设计模式的重要性
解决通用问题:提供标准化的方法,减少重复造轮子。
提高可维护性:鼓励编写可扩展、易维护的代码。
增强可读性:为开发团队提供共同语言,便于沟通。
应对变化:设计灵活的系统,适应业务需求变化。
减少错误:使用经过实践验证的解决方案,避免常见错误。
设计模式的分类
创建型模式:关注对象的创建,典型的有工厂模式、单例模式等。
结构型模式:处理对象之间的关系,如装饰器模式、代理模式等。
行为型模式:涉及对象之间的交互和职责分配,如观察者模式、策略模式等。
学习设计模式
经典书籍:如《设计模式:可复用面向对象软件的基础》。
实践应用:将理论应用于项目中,理解优缺点。
代码阅读:分析开源项目,学习设计模式的实际应用。
重构练习:尝试重构已有代码,深化理解。
逐步引入:根据项目需要逐步引入设计模式。
同行讨论:与其他开发者交流,拓展视野。
七项基本原则
单一职责原则 (SRP):一个类只应有一个职责,降低复杂性和提高可维护性。
开放-关闭原则 (OCP):软件实体应对扩展开放,对修改关闭,以增强系统灵活性和稳定性。
里氏替换原则 (LSP):子类应能替代父类,保持功能一致,避免对父类行为的破坏。
接口隔离原则 (ISP):客户端不应被强迫依赖于它不使用的接口,鼓励小而专用的接口设计。
依赖倒置原则 (DIP):高层模块不应依赖低层模块,二者应依赖于抽象;抽象不应依赖于细节,细节应依赖于抽象。
合成复用原则 (CRP):尽量通过组合和聚合的方式来复用,而不是通过继承。
迪米特法则 (LoD):一个对象应尽量少了解其他对象,降低模块之间的耦合度。
设计模式是解决软件开发中复杂性的重要工具,通过学习和实践这些模式,开发者能够编写出更清晰、可扩展和可维护的代码,从而提高开发效率和代码质量。理解并运用设计原则有助于更好地实现这些模式。
而我们今天重点讲解的观察者模式是一种行为型设计模式,定义了一种一对多的依赖关系,使得当一个对象的状态发生变化时,所有依赖于它的对象都会自动收到通知并更新。这个模式通常用于实现事件系统或消息通知机制。
用途
事件监听:观察者模式常用于 GUI 应用程序中的事件处理,如按钮点击、文本输入等。不同的组件可以注册为观察者,以响应用户的操作。
数据模型的变化通知:在 MVC(模型-视图-控制器)架构中,模型的变化需要通知视图进行更新。观察者模式使得模型和视图之间的耦合度降低。
实时数据更新:在金融、气象等应用中,数据源的变化需要实时更新显示的内容。观察者模式允许多个显示组件订阅数据源,并在数据更新时自动刷新。
消息推送:在分布式系统或微服务架构中,观察者模式可用于实现消息推送,允许服务间进行异步通信。
日志系统:可以使用观察者模式来实现日志记录。当系统发生特定事件时,多个观察者(如文件、控制台、远程服务器等)都可以记录该事件。
价值
解耦合:观察者模式将主题(被观察者)和观察者(订阅者)解耦,主题不需要知道具体的观察者,实现了高内聚和低耦合。
灵活性:可以轻松添加、删除观察者,而不需要修改主题的代码,增强了系统的灵活性和可扩展性。
动态交互:允许在运行时动态地添加或移除观察者,适应不断变化的需求。
多对多关系:允许多个观察者同时观察同一个主题,使得系统能够处理复杂的交互关系。
提高可维护性:通过将业务逻辑分离到观察者中,使得系统更加模块化,便于理解和维护。