SQL Server
6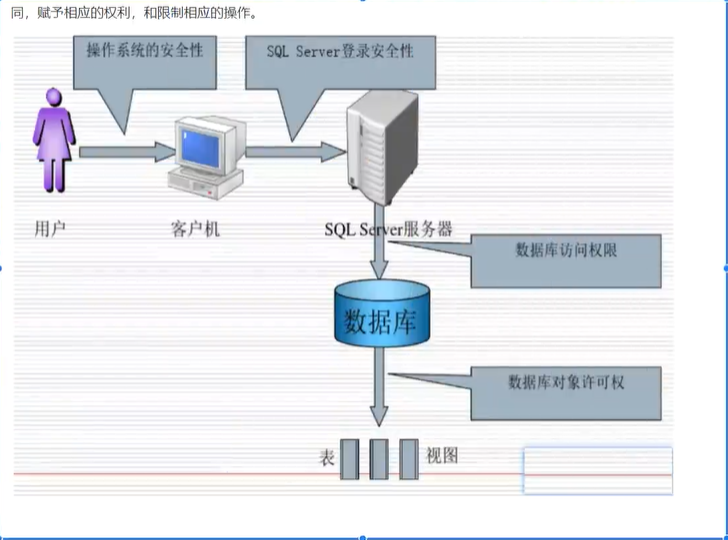
SQLServer基本操作
打开数据库
数据库的基本操作
1.建库
2.建表
3.数据维护
数据库的迁移
1. 数据库的分离,附加
2.数据库的备份
3.数据库脚本的保存
脚本建库建表
1.创建数据库
//创建数据库
create database 你的数据库名字
on //设定数据文件
(
name = '你的逻辑文件名字'
filename = 'D:....\nD:....\你的文件名字.mdf'//物理路径
size = 5MB,//文件初始大小
filerowth = 2MB//文件增长方式可以写大小,也可以写百分比
)
log on
(
name = '你的逻辑文件名字_log'
filename = 'D:....\nD:....\你的文件名字_log.ldf'//物理路径
size = 5MB,//文件初始大小
filerowth = 2MB//文件增长方式可以写大小,也可以写百分比
)
//创建数据库(简写)
create database 你的数据库名字
//on log on 里里面的东西有默认值 2.删除数据库
if exists(select * from sys.database where name = '你的数据库名字' )
drop database 你的数据库名字3.创建表
//切换数据库
use 你想要的数据库名字
//创建表的基本语法
create table 表名
(
字段名1 数据类型
......
)
//实例建表
if exists (select *from sys.objects where name = '你的表名' and type = 'U')
drop table 你的表名
create table DepartmentID
(
//部门编号,primary key(用来标识主键),identity(1,1):自动增长,初始值1,加1
id int primary key identity(1,1),
name nvarchar(50) not null,
......
)
create table people
(
People int primary key identity(1,1),
DepartmentID int references Department(DepartmentID) not null,//references与上面的表产生联系(引用外键)
PeopleSex nvarchar(1) default('男')check(PeopleSex = '男' or PeopleSex = '女') not null ,//default不填的时候有默认值,check产生选择
PeopleBirth smalldatatime not null,//smalldatetime 可填近段时间内的时间太久远的时间填补不上去
Peoplenum varchar(20) unique not null,
PeopleAddTime smalldatetime default (getdate())
)//添加自动生成当前时间数据类型


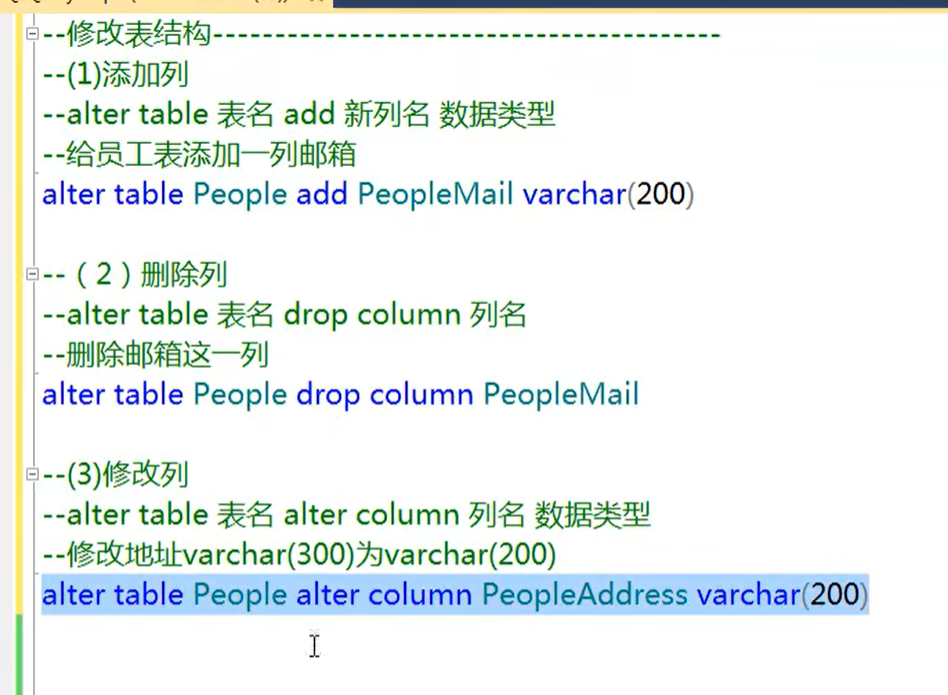
修改表结构


数据的增删改查
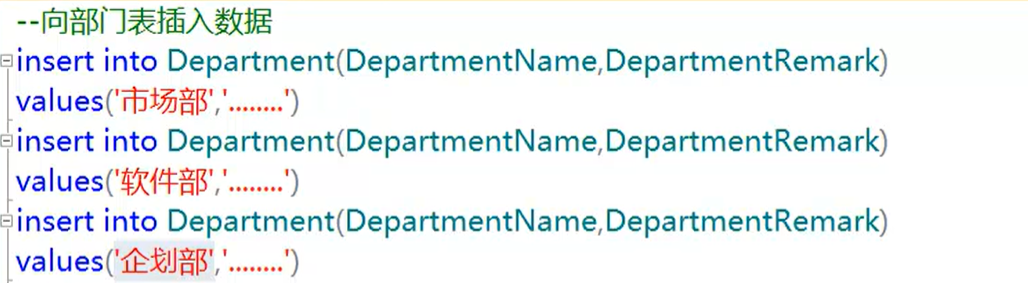
插入数据

修改数据

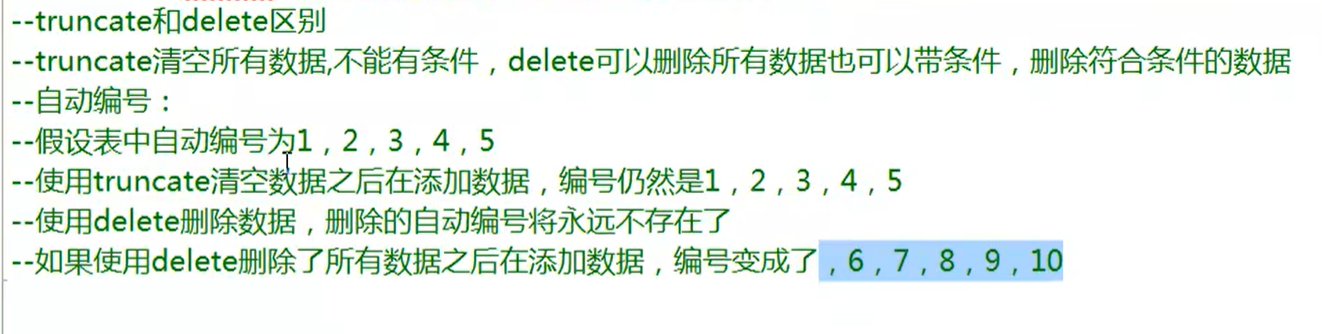
删除数据


查询数据
基本查询


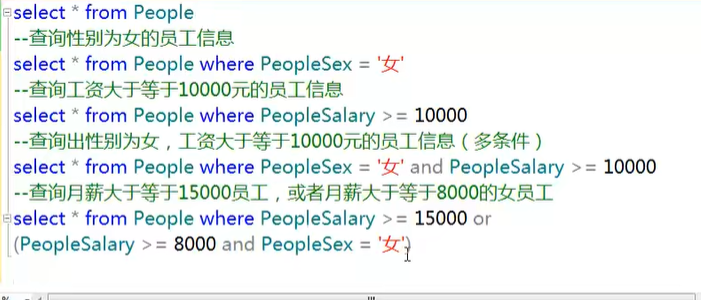
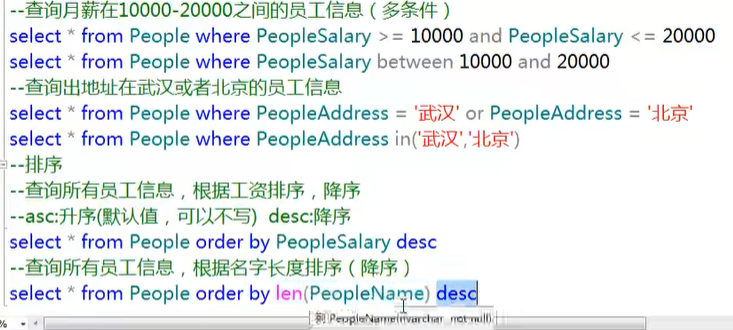
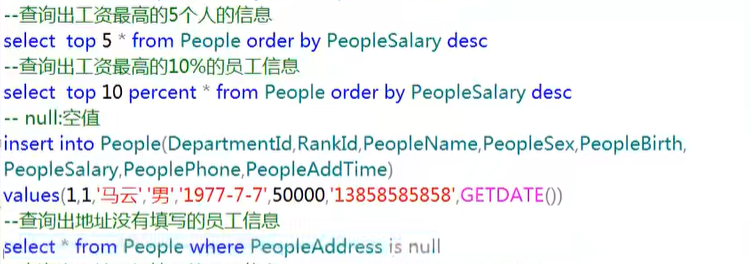
条件查询
常见的运算符




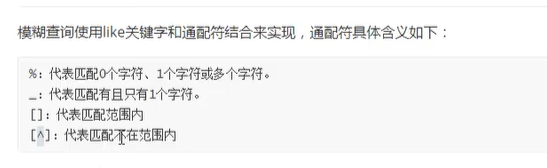
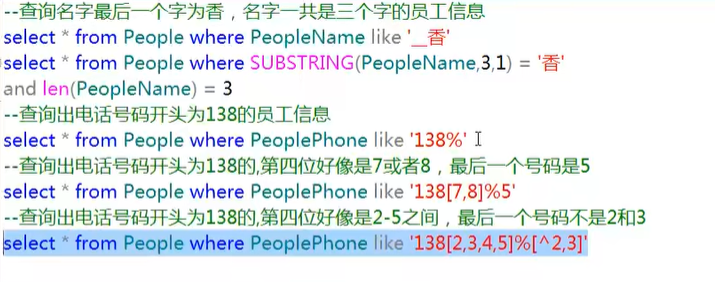
模糊查询

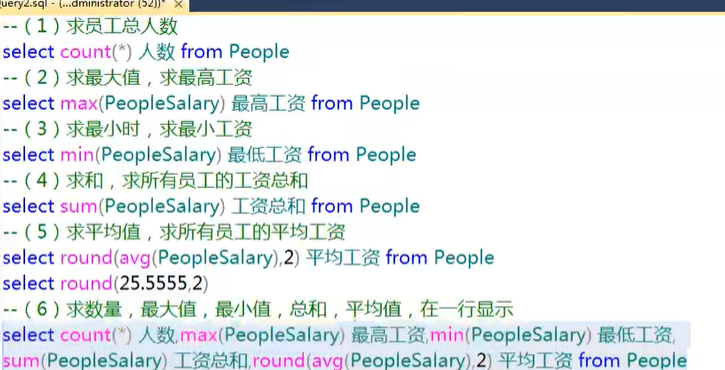
聚合函数



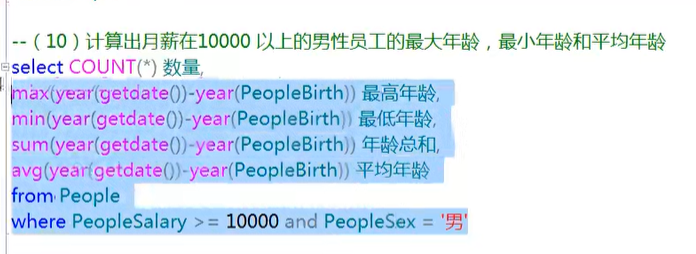

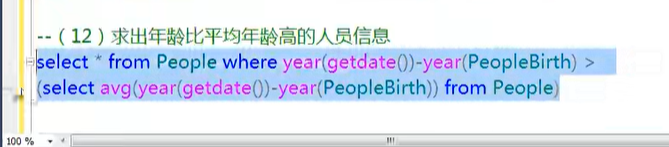
分组查询




多表查询
简单的多表查询

内连接查询

外连接查询
左外连

右外连

全外连

例子





自连接

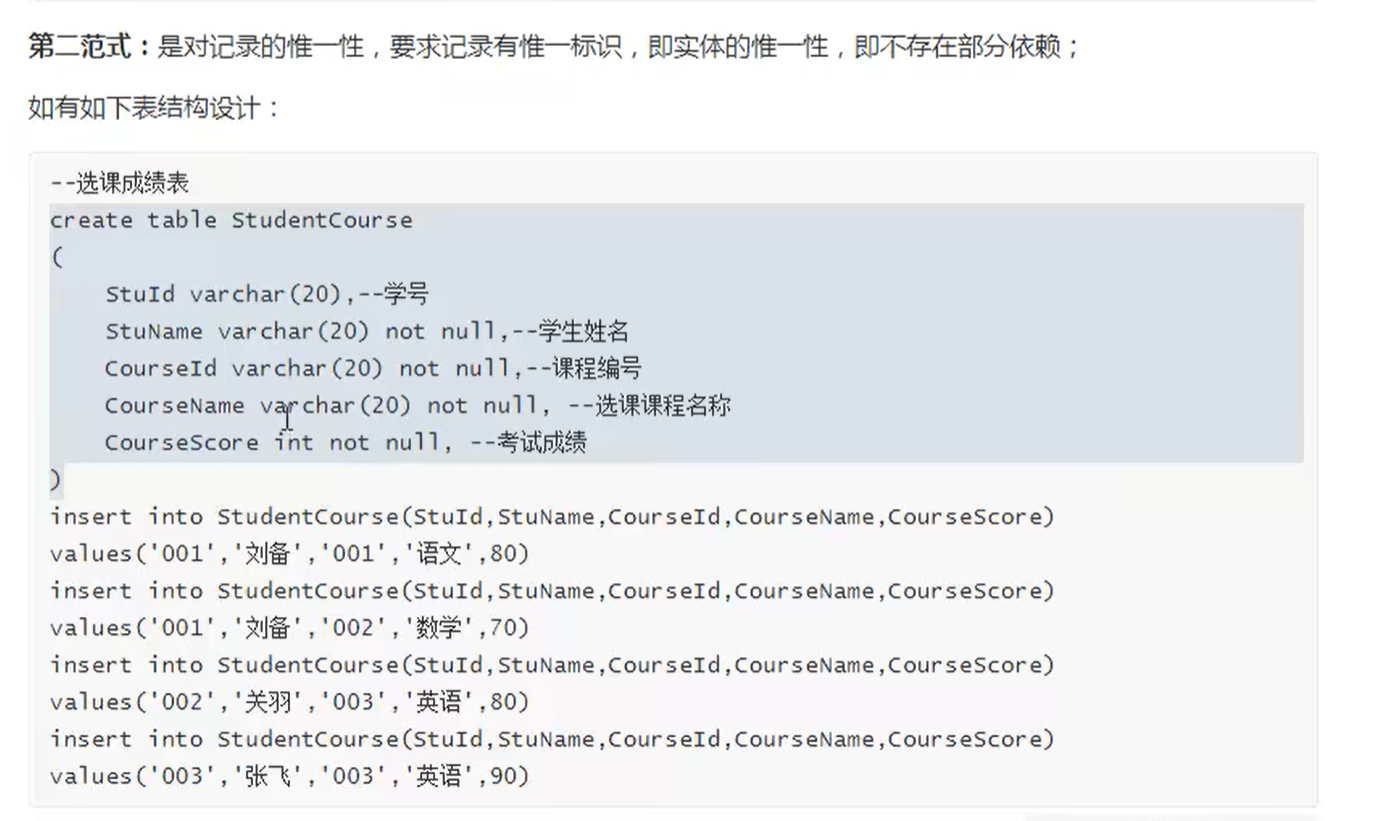
三范性



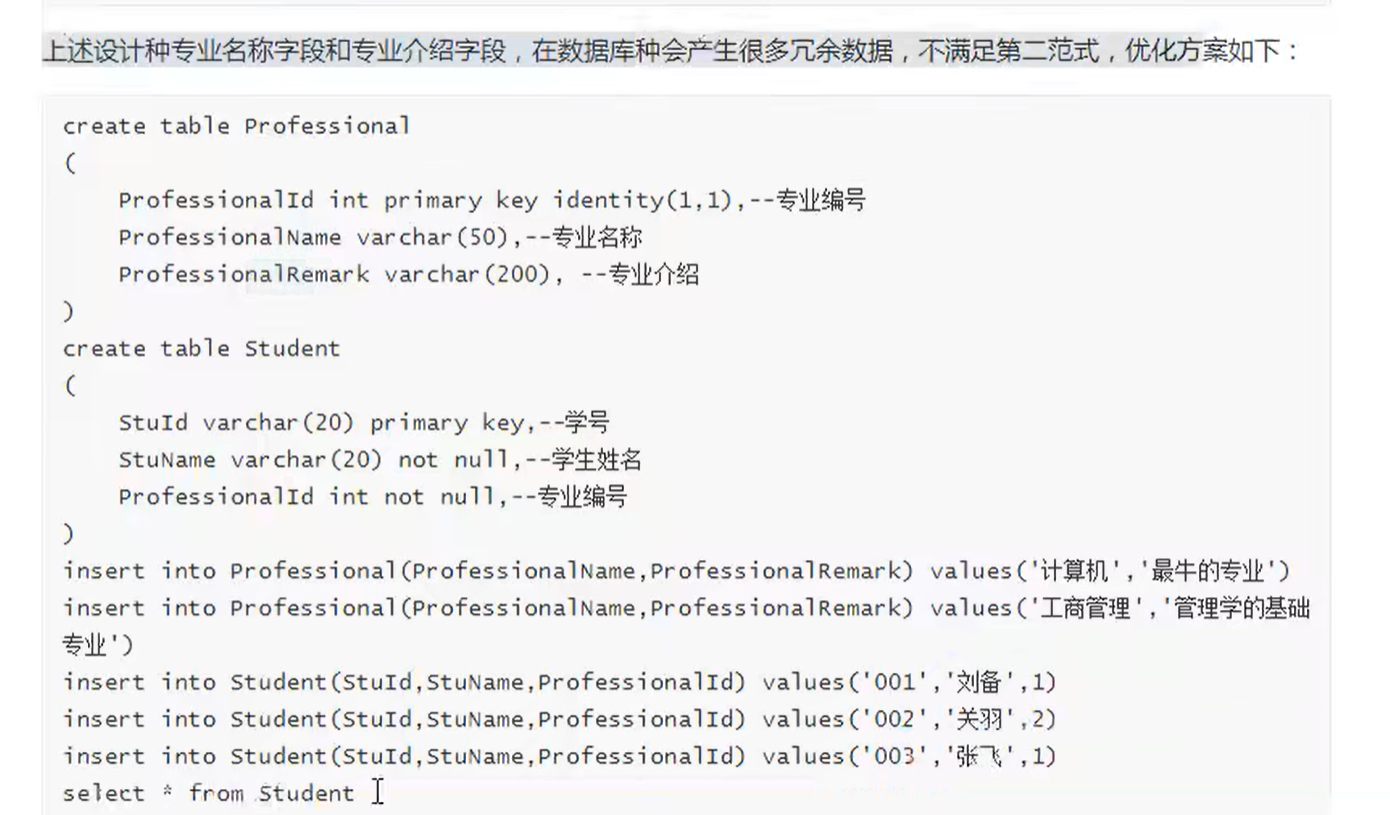
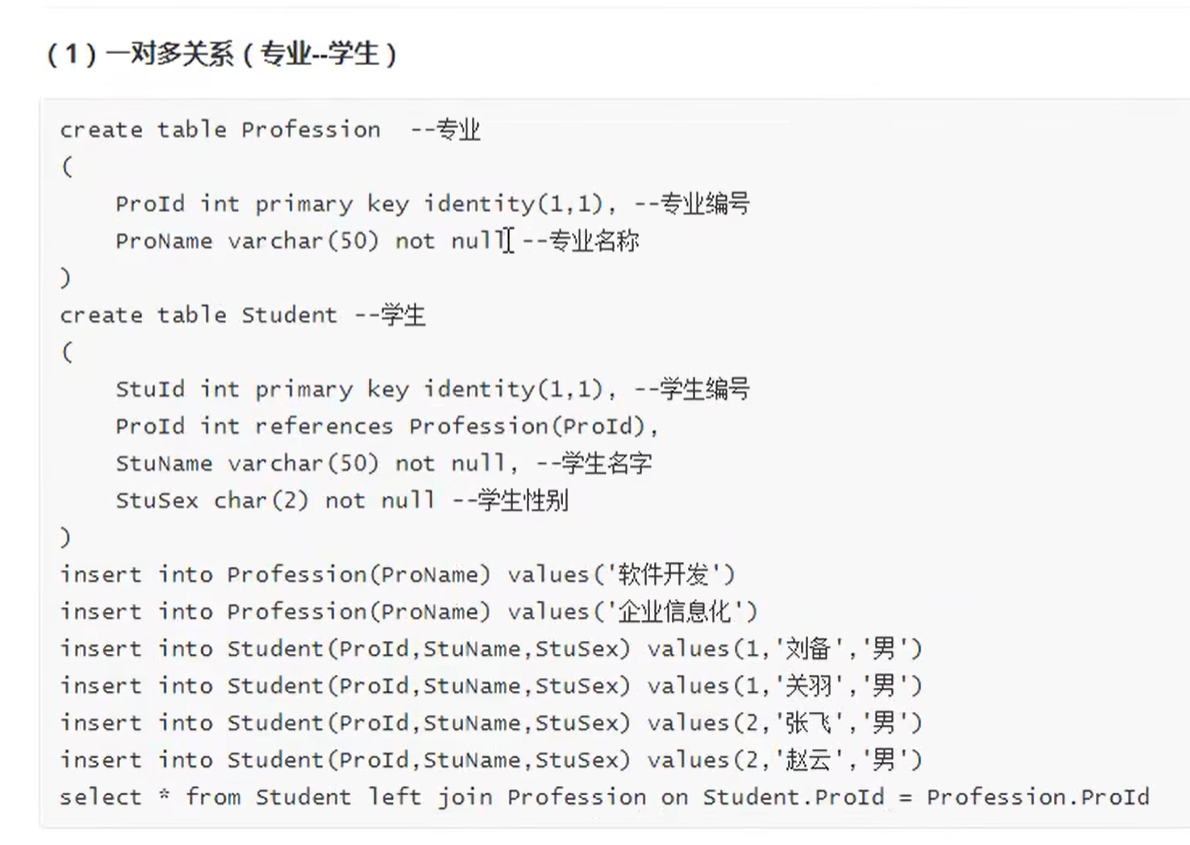
表关系


T-SQL语法

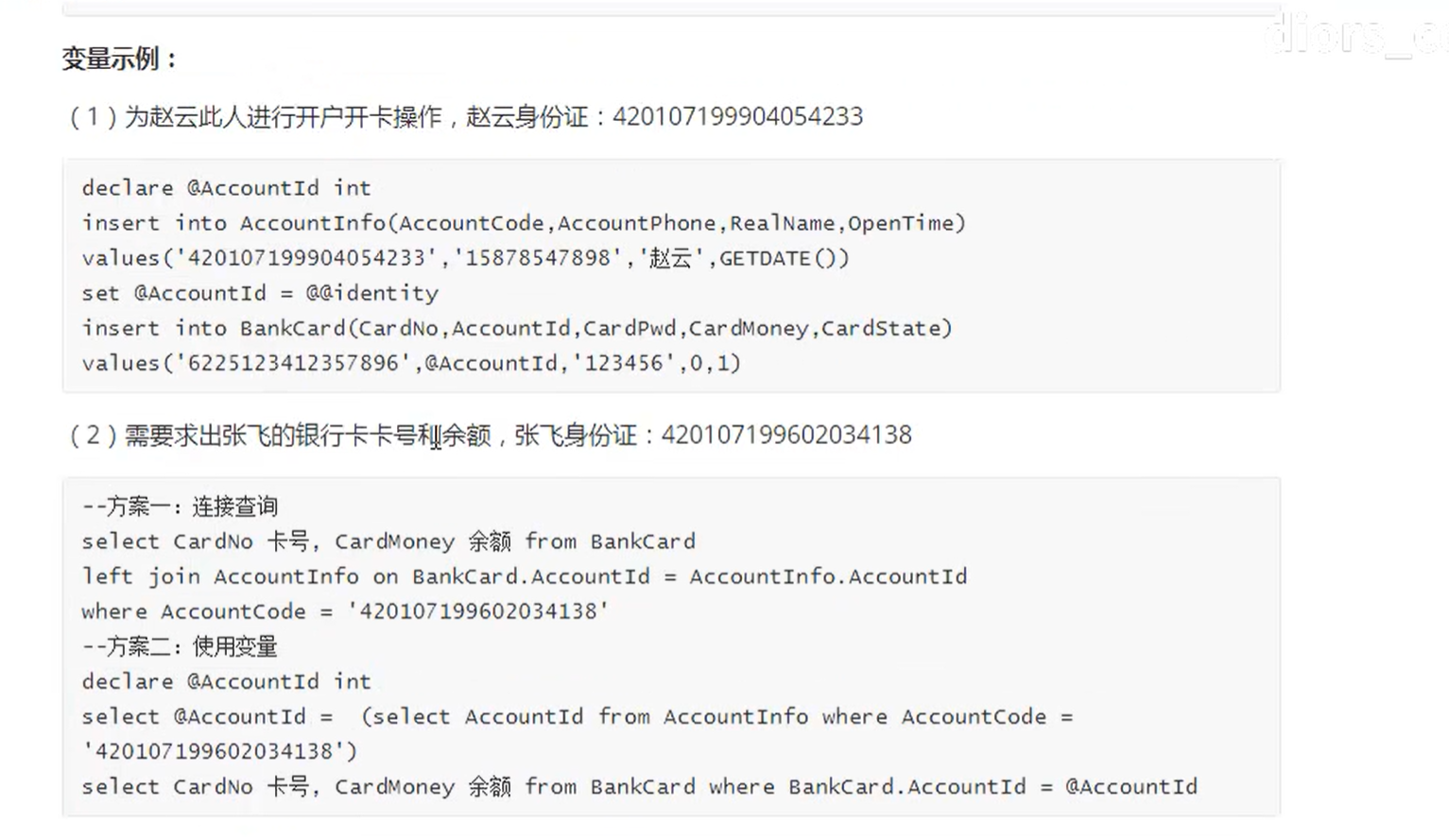


运算符

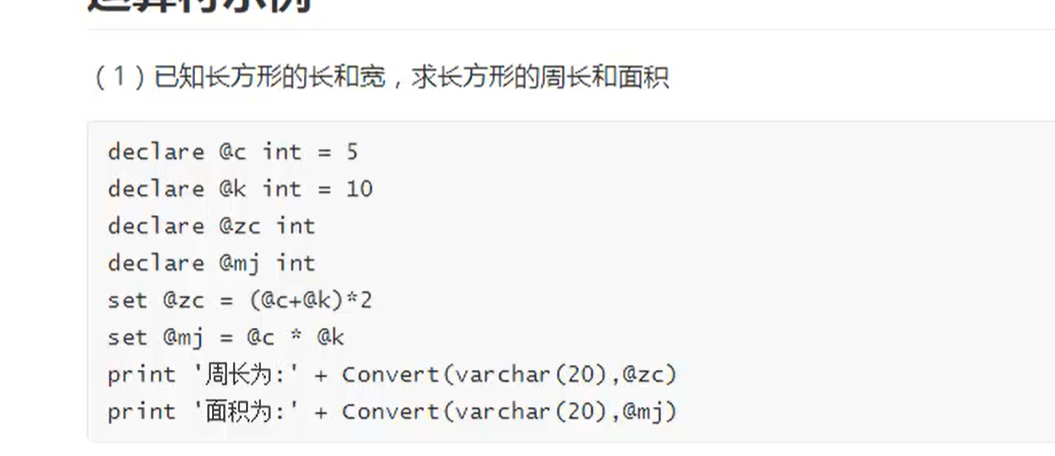
(Convert)——类型转换
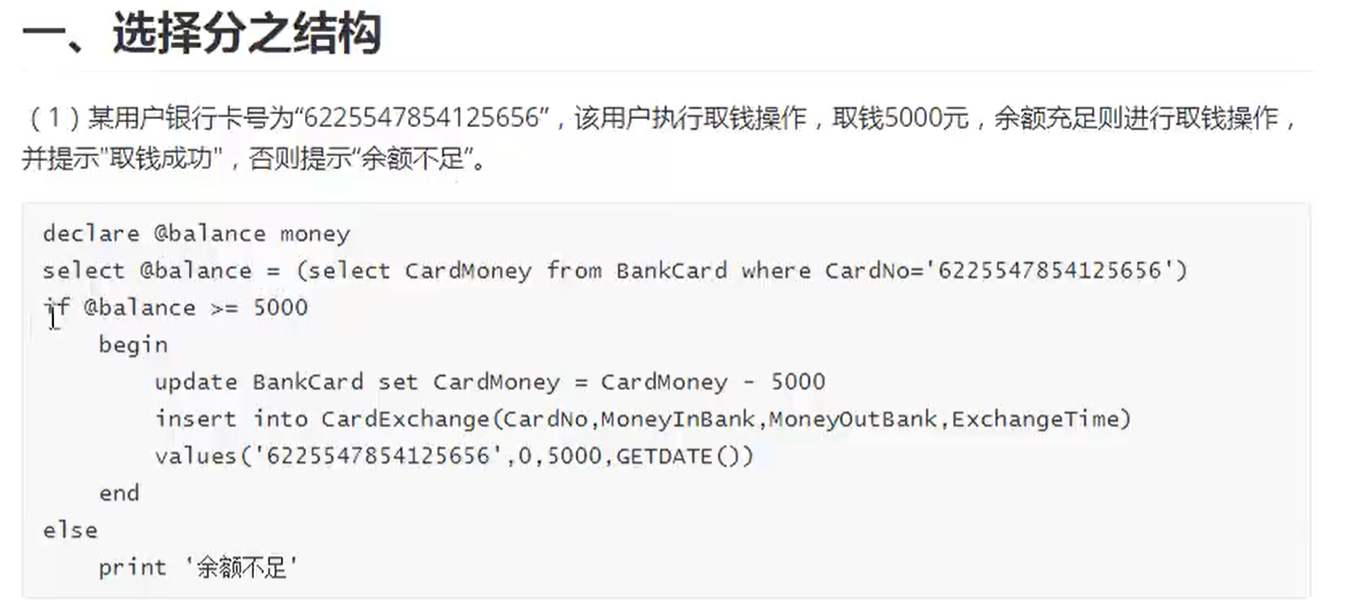
流程控制
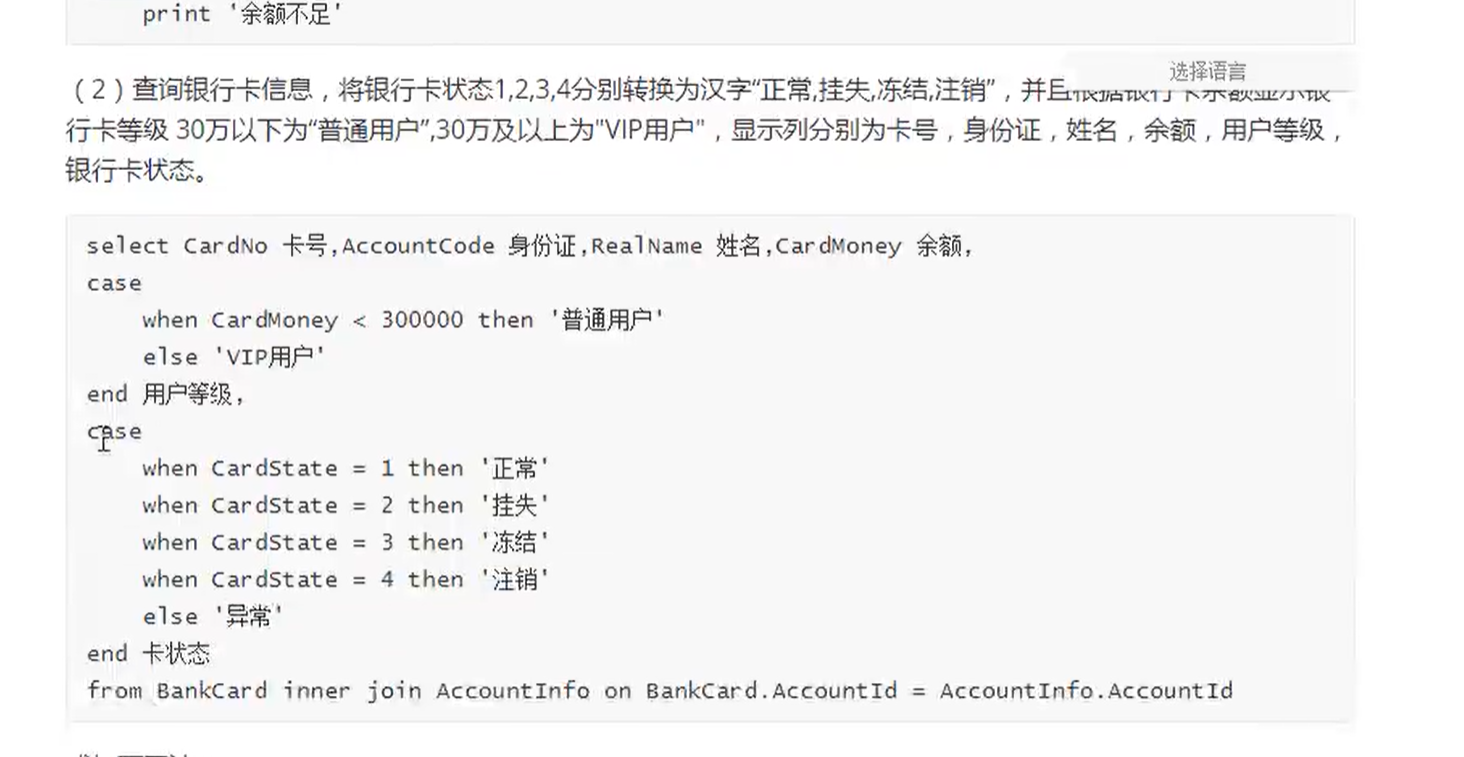
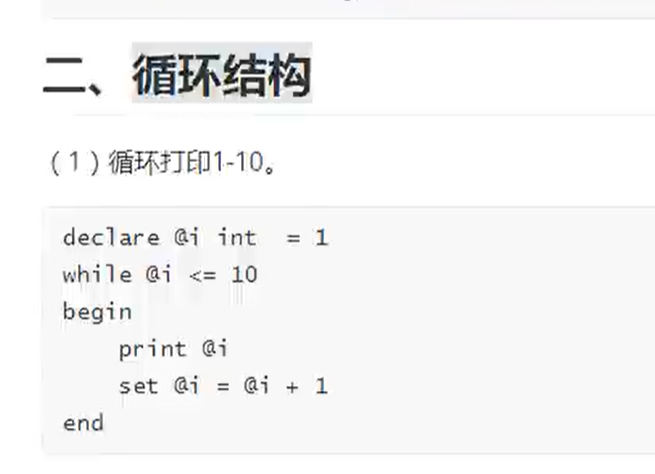
子查询
分页


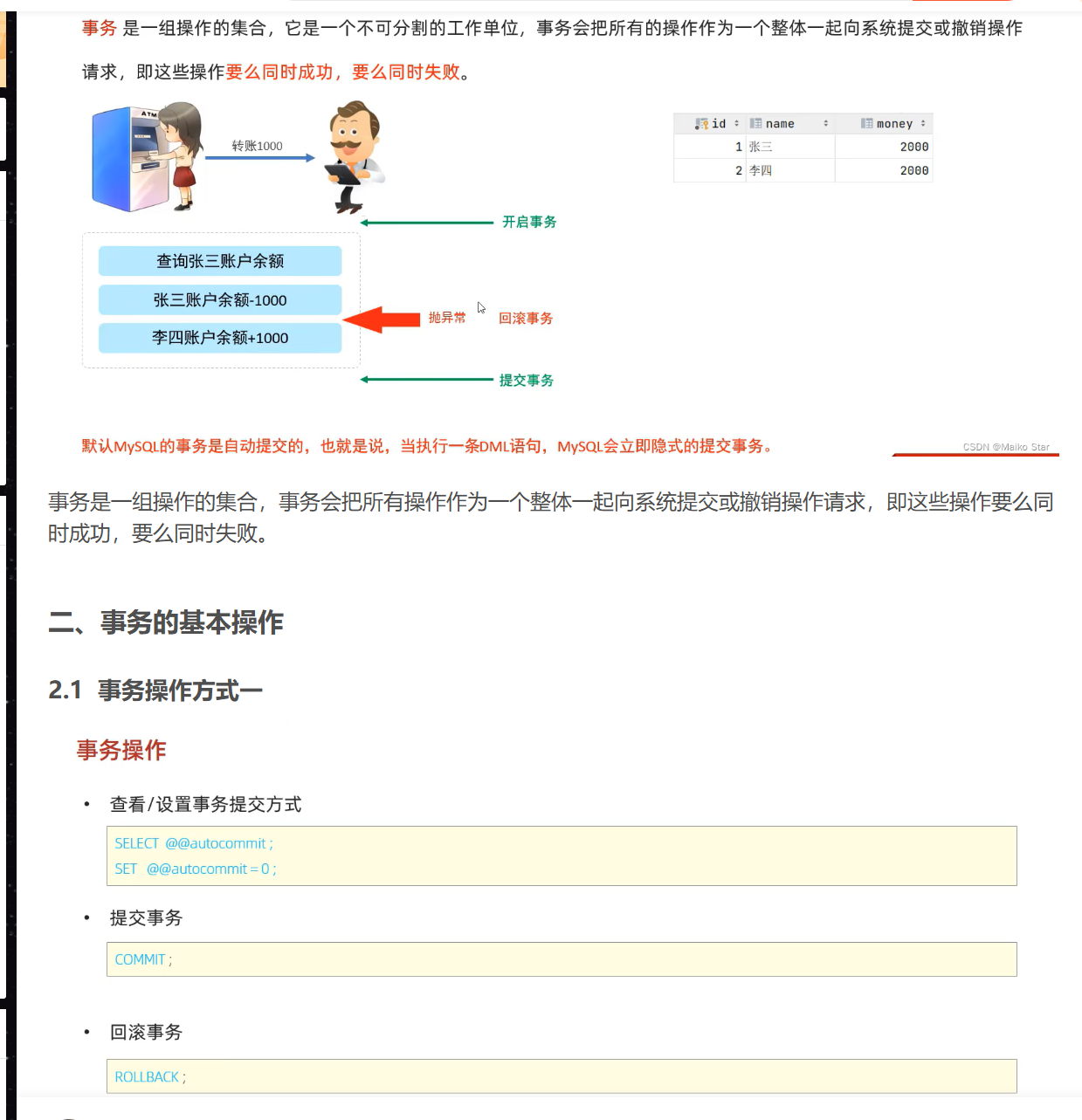
事务
索引

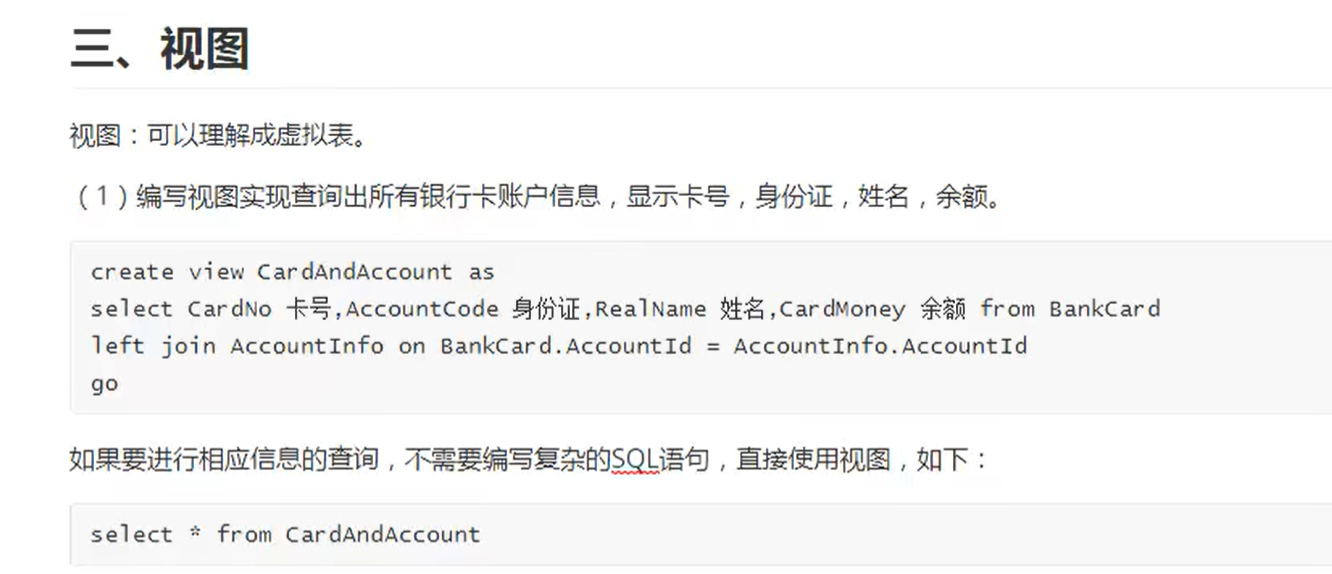
视图
游标
一、什么是“游标(Cursor)”?
游标是SQL 的一种数据访问机制 ,游标是一种处理数据的方法。众所周知,使用SQL的select查询操作返回的结果是一个包含一行或者是多行的数据集,如果我们要对查询的结果再进行查询,比如(查看结果的第一行、下一行、最后一行、前十行等等操作)简单的通过select语句是无法完成的,因为这时候索要查询的结果不是数据表,而是已经查询出来的结果集。游标就是针对这种情况而出现的。
我们可以将“ 游标 ”简单的看成是结果集的一个指针,可以根据需要在结果集上面来回滚动,浏览我需要的数据。
二、游标的操作——五步走
声明游标—>打开游标—>读取数据—>关闭游标—>删除游标
1、声明游标——Declare cursorname Cursor
语法如下:
declare cursor_name Corsor [ LOCAL | GLOBAL] [ FORWARD_ONLY | SCROLL ] [ STATIC | KEYSET | DYNAMIC | FAST_FORWARD ] [ READ_ONLY | SCROLL_LOCKS | OPTIMISTIC ] [ TYPE_WARNING ]
for
Slect查询的相关语句
上面的彩色字体表示的是,声明游标时的选项,不是必须提供的,每一个都代表游标的相关选项和特性
(1)LOCAL:对于在其中创建批处理、存储过程或触发器来说,该游标的作用域是局部的。GLOBAL:指定该游标的作用域是全局的
(2)FORWARD_ONLY:指定游标只能从第一行滚动到最后一行。否则默认为FORWARD_ONLY。SCROLL表示游标可以来回滚动
(3)STATIC:定义一个游标,以创建将又该游标使用的数据临时复本,对游标的所有请求都从tempdb中的这以临时表中不得到应答;因此,在对该游标进行提取操作时返回的数据中不反映对基表所做的修改,并且该游标不允许修改。
KEYSET:指定当游标打开时,游标重的行的成员身份和顺序已经固定。对行进行唯一标识的键值内置在tempdb内一个称为keyset的表中。
DYNAMIC:定义一个游标,以反映在滚动游标时对结果集内的各行所做的所有数据更改。行的数据值、顺序和成员身份在每次提取时都会更改,动态游标不支持ABSOLUTE提取选项。
FAST_FORWARD:指定启动了性能优化的FORWARD_ONLY、READ_ONLY游标。如果指定了SCROLL或FOR_UPDATE,则不能指定FAST_FORWARD。
SCROLL_LOCKS:指定通过游标进行的定位更新或删除一定会成功。将行读入游标时SQL Server将锁定这些行,以确保随后可对它们进行修改,如果还指定了FAST_FORWARD或STATIC,则不能指定SCROLL_LOCKS。
OPTIMISTIC:指定如果行自读入游标以来已得到更新,则通过游标进行的定位更新或定位删除不成功。当将行读入游标时,SQL Server不锁定行,它改用timestamp列值比较结果来确定行读入游标后是否发生了修改,如果表不包含timestamp列,它改用校验和值进行确定,如果以修改该行,则尝试进行的定位更新或删除将失败,如果还指定了FAST_FORWARD,则不能指定OPTIMISTIC。
TYPE_WARNING:指定游标从所请求的类型隐式转换为另一种类型时,向客户端发送警告消息。
2、打开游标——Open Cursorname
3、取出数据——Fetch.........From
Fetch [ NEXT | PRIOR | FIRST | LAST | ABSOLUTE { n | @nvar } | RELATIVE { n | @nvar }] FROM Cursorname
[ INTO @variable_name [ ,...n ] ]
NEXT:紧跟当前行返回结果行,并且当前行递增为返回行,如果FETCH NEXT为对游标的第一次提取操作,则返回结果集中的第一行。NEXT为默认的游标提取选项。
PRIOR:返回紧邻当前行前面的结果行,并且当前行递减为返回行,如果FETCH PRIOR为对游标的第一次提取操作,则没有行返回并且游标置于第一行之前。
FIRST:返回游标中的第一行并将其作为当前行。
LAST:返回游标中的最后一行并将其作为当前行。
ABSOLUTE { n | @nvar }:如果n或@nvar为正,则返回从游标头开始向后n行的第n行,并将返回行变成新的当前行。如果n或@nvar为负,则返回从游标末尾开始向前的n行的第n行,并将返回行变成新的当前行。如果n或@nvar为0,则不返回行。n必须是整数常量,并且@nvar的数据类型必须为int、tinyint或smallint.
RELATIVE { n | @nvar }:如果n或@nvar为正,则返回从当前行开始向后的第n行。如果n或@nvar为负,则返回从当前行开始向前的第n行。如果n或@nvar为0,则返回当前行,对游标第一次提取时,如果在将n或@nvar设置为负数或0的情况下指定FETCH RELATIVE,则不返回行,n必须是整数常量,@nvar的数据类型必须是int、tinyint或smallint.
GLOBAL:指定cursor_name是全局游标。
cursor_name:已声明的游标的名称。如果全局游标和局部游标都使用cursor_name作为其名称,那么如果指定了GLOBAL,则cursor_name指的是全局游标,否则cursor_name指的是局部游标。
@cursor_variable_name:游标变量名,引用要从中进行提取操作的打开的游标。
INTO @variable_name [ ,...n ]:允许将提取操作的列数据放到局部变量中。列表中的各个变量从左到右与游标结果集中的相应列相关联。各变量的数据类型必须与相应的结果集列的数据类型相匹配,或是结果集列数据类型所支持的隐士转换。变量的数目必须与游标选择列表中的列数一致。
4、关闭游标——Close Cursorname
5、删除游标——Deallocate Cursorname
触发器
什么是触发器
MySQL触发器(Trigger)是一种特殊的存储过程,
它与表有关,当表上的特定事件(insert,update,delete)发生时,触发器会自动执行。
可以使用触发器来实现数据约束,数据验证,数据复制等功能
为什么使用触发器
可以实现数据约束,数据验证,数据复制等功能
例如:
可以创建一个触发器,在向表中插入一条记录时,自动向另一个表中插入一个记录,从而实现数据复制的功能。
触发器还可以用于实现数据验证,
例如
在插入或更新数据时,检查记录的某些字段是否符合要求,则拒绝插入或者更新,这样可以保证数据的完整性和一致性。
创建触发器
语法:
create trigger 触发器名称
{before | after } {insert | update | delete} -- 触发器类型和事件
on 表名称
for each row -- 触发器的作用范围
begin
-- 触发器执行的操作
end;
1
2
3
4
5
6
7
触发器名称可以自定义 ,并唯一性,见名知意
before / after : 表示触发器的类型,分别表示发生前/发生后执行
insert / update / delete : 表示触发器的事件类型,分别表示插入 / 更新 / 删除操作
on 表名称 : 为触发器所在的表名
for each row : 表示触发器作用的范围,即每一行记录都会触发该触发器
begin 和 end之间是触发器执行的操作,可以是一条或者多条SQL语句
触发器是自动执行的,无需手动调用,
当表上的特定事件(insert , update, delete ) 发生时,触发器会自动执行
在创建触发器时,可以定义触发器的类型和事件,从而控制触发器的时机和条件
案例:
-- 创建两张表
create table table1(
id int,
name varchar(20) character set utf8
)charset = utf8;
create table table2(
id int,
name varchar(20) character set utf8
)charset = utf8;
1
2
3
4
5
6
7
8
9
10
添加事件
-- 创建一个触发器,当向表中插入一条记录时,自动向另一个表中插入一条记录
create trigger insert_trigger_1
after insert on table1
for each row
begin
-- 触发器的具体事件
insert into table2(id,name) values (NEW.id,New.name);
end;
1
2
3
4
5
6
7
8
添加数据:
向table1表中添加数据时,会触发insert_trigger_1触发器,自动向table2表中添加数据
insert into table1(id,name) values (1,'张三'),(2,'李四'),(3,'王五'),(4,'赵六'),(5,'唐七'),(6,'老王');
1
查询table1表
select * from table1;
1
查询table2表
select * from table2;
1
删除事件
-- 创建一个触发器,当从表中删除一条记录时,自动从另一个表中删除一条记录
create trigger delete_trigger_1
after delete on table1
for each row
begin
delete from table2 where id = OLD.id and name = OLD.name;
end;
1
2
3
4
5
6
7
删除数据:
删除table1表中数据时,会触发delete_trigger_1触发器,自动删除table2表中对应的数据
delete from table1 where id = 5 and name = '王五';
1
查看两张表中的数据
select * from table1;
1
select * from table2;
1
修改事件
-- 创建一个触发器,当向表中更新一条记录时,自动更新另一个表中的记录
create trigger update_trigger_1
after update on table1
for each row
begin
update table2 set id = NEW.id, name = NEW.name where id = OLD.id and name = OLD.name;
end;
1
2
3
4
5
6
7
修改数据:
修改table1表中数据时,会触发update_trigger_1触发器,自动更新table2表中对应的数据
update table1 set id = 10,name = '小明' where id = 6 and name = '老王';
1
select * from table1;
1
select * from table2;
1
删除触发器
drop trigger 触发器名称;
1
触发器的应用场景
触发器的应用场景包括但不限于以下几种:
强制实施业务规则:通过在触发器中编写逻辑,可以在特定的表上自动执行业务规则,例如检查输入的数据是否符合要求,或者限制某些操作的执行。
记录日志变更:通过在触发器中编写逻辑,可以在特定的表上自动记录数据的变更情况,例如记录数据的修改时间、修改人等信息。
复杂的默认值计算:通过在触发器中编写逻辑,可以在特定的表上自动计算默认值,例如根据其他字段的值计算出一个新的字段的值。
数据同步:通过在触发器中编写逻辑,可以在多个表之间自动同步数据,例如在一个表中插入一条数据时,自动在另一个表中插入相应的数据。
数据校验:通过在触发器中编写逻辑,可以在特定的表上自动校验数据的正确性,例如检查数据的唯一性、完整性等。
总结:
触发器的应用场景非常广泛,可以用于强制实施业务规则、记录日志变更、复杂的默认值计算、数据同步以及数据校验等。在创建触发器时,需要指定触发器的名称、触发器所在的表、触发器的触发时机(如insert、update或delete操作)、触发器的执行次数(for each row或for each row statement)以及触发器的逻辑。