线性回归算法补充
过拟合与欠拟合问题
在线性回归用于预测一个或多个自变量(特征)与因变量(目标变量)之间的线性关系的实际应用中,线性回归模型可能会遇到两个主要问题:过拟合和欠拟合。这两个问题直接关系到模型的泛化能力,即在未见过的数据上的表现。
一、过拟合与欠拟合的定义
过拟合:当模型在训练数据上表现得过于精确,以至于它捕捉到了训练数据中的噪声和异常值,而不是数据中的潜在规律时,就发生了过拟合。过拟合的模型在训练集上表现很好,但在测试集或新数据上表现糟糕,因为它没有很好地泛化到未见过的数据。
欠拟合:与过拟合相反,欠拟合发生在模型过于简单,无法捕捉到数据中的复杂关系时。欠拟合的模型在训练集和测试集上的表现都很差,因为它没有充分学习数据的特征。
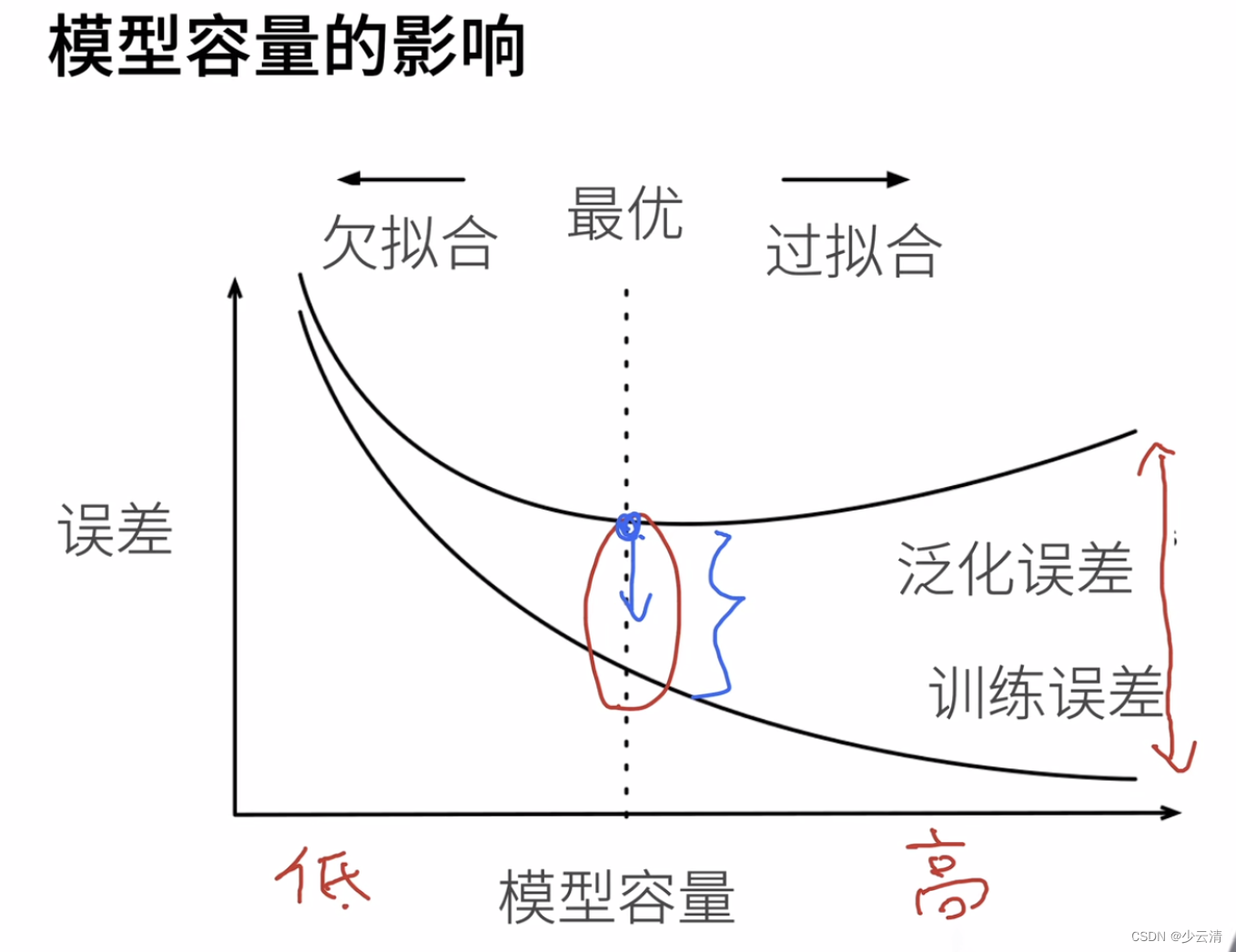
二、线性回归中的过拟合与欠拟合
在线性回归中,过拟合和欠拟合通常与模型的复杂度有关。模型的复杂度可以通过特征的数量、多项式项的阶数等因素来衡量。
欠拟合:如果线性回归模型的特征数量太少,或者没有包含足够的高阶多项式项来捕捉数据的非线性关系,模型可能会过于简单,导致欠拟合。
过拟合:相反,如果模型包含了太多的特征,或者使用了过高的多项式阶数,模型可能会变得过于复杂,以至于它开始捕捉训练数据中的噪声,导致过拟合。
模型的泛化能力:机器学习模型学习到的概念在它处于学习的过程中时模型没有遇见过的样本时候的表现。
模型的泛化能力直接导致了模型会过拟合与欠拟合的情况。
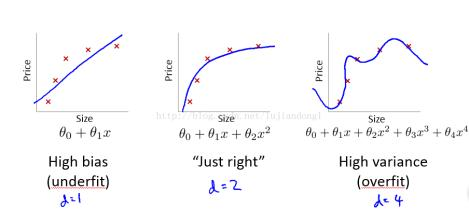
我们的目标是要实现点到直线的平方和最小,那通过以上图示显然可以看出中间那幅图的拟合程度很好,最左边的情况属于欠拟合,最右边的情况属于过拟合。
三、识别过拟合与欠拟合
识别线性回归模型是否过拟合或欠拟合,通常通过观察模型在训练集和测试集上的表现来实现。
训练集和测试集上的误差:如果模型在训练集上表现良好,但在测试集上表现较差,这通常是过拟合的迹象。相反,如果模型在训练集和测试集上都表现不佳,这可能是欠拟合的表现。
残差图:残差是实际值与预测值之间的差异。通过绘制残差图,可以观察模型在不同区域的拟合情况。如果残差在训练数据的不同部分呈现出不同的模式(如非线性趋势或异常值),这可能表明模型过拟合或欠拟合。
四、解决方法
使用正则化项,也就是给梯度下降公式加上一个参数,即:
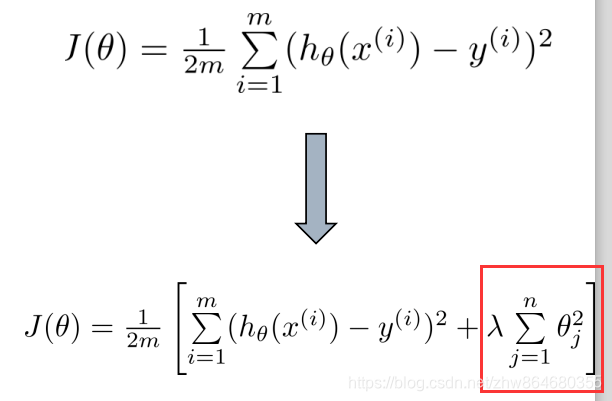
或者
——进行特征选择,消除关联性大的特征
——交叉验证(让所有数据都有过训练)