YOLOv10导入可变形卷积(DCNv4)
DCNv4是一种为广泛的视觉应用设计的高效且有效的算子,因其可变形的特性而对一些形状不规则的小目标的检测有着较好的效果。DCNv1和DCNv2导入都较为简单,直接在模块中添加即可,但DCNv4则需要编译后才能使用。下文将介绍如何在YOLOv10中导入DCNv4。
YOLOv10添加DCNv4的方法
1、下载代码:
代码地址:GitHub - OpenGVLab/DCNv4: [CVPR 2024] Deformable Convolution v4
也可以使用git下载:git clone https://github.com/OpenGVLab/DCNv4.git
下载完后将代码复制到 ultralytics\nn\modules 目录下
2、编译代码:
打开终端切换工作路径到 ultralytics/nn/modules/DCNv4/DVNv4_op
输入以下代码进行编译:python setup.py build install
请注意,在编译前确保自己的环境中已经下载了cuda和其相适配的PyCharm,否则编译会报错
3、代码整合
在 ultralytics\nn\modules\block.py 中添加下述代码
import torch.nn as nn
import torch
from ultralytics.nn.modules.DCNv4.DCNv4_op.DCNv4.modules.dcnv4 import DCNv4
from ultralytics.nn.modules.conv import Conv
class Bottleneck(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, and
expansion.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = DCNv4(c2)
self.add = shortcut and c1 == c2
def forward(self, x):
"""'forward()' applies the YOLO FPN to input data."""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C2f_DCNv4(nn.Module):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,
expansion.
"""
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=(3, 3), e=1.0) for _ in range(n))
def forward(self, x):
"""Forward pass through C2f layer."""
x = self.cv1(x)
x = x.chunk(2, 1)
y = list(x)
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""Forward pass using split() instead of chunk()."""
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
在上方添加C2f_DCNv4
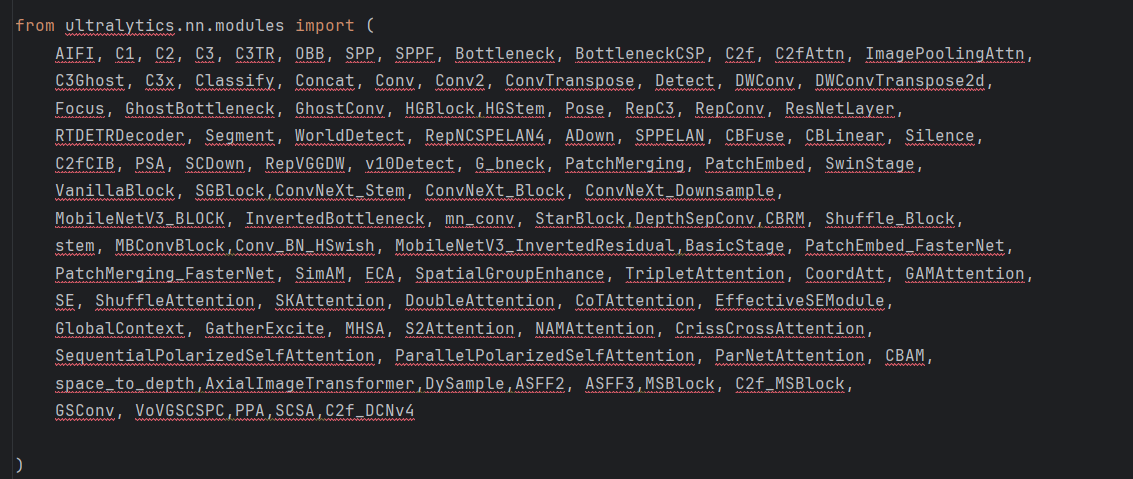
在 ultralytics\nn\modules\__init__.py中添加C2f_DCNv4
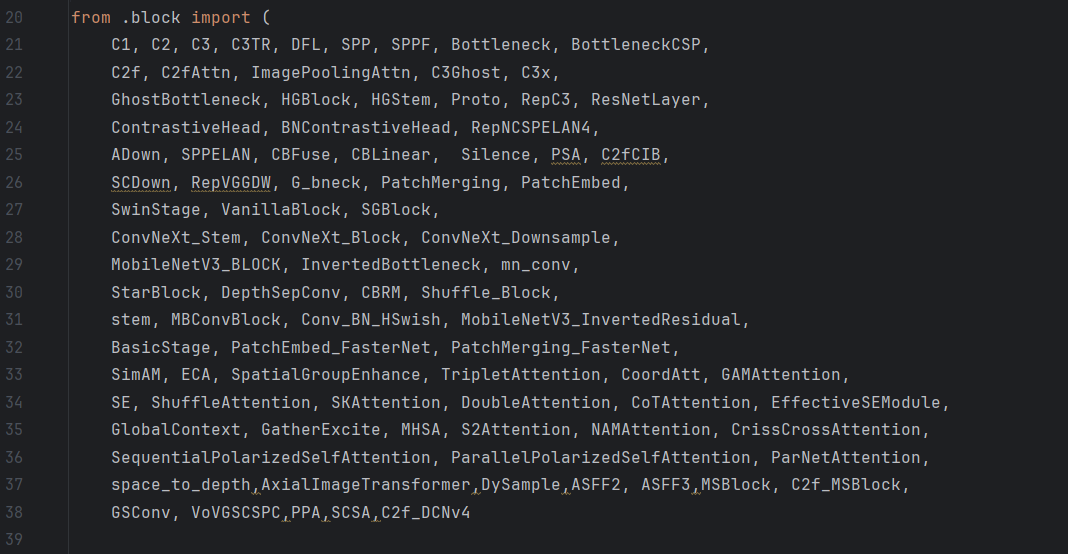
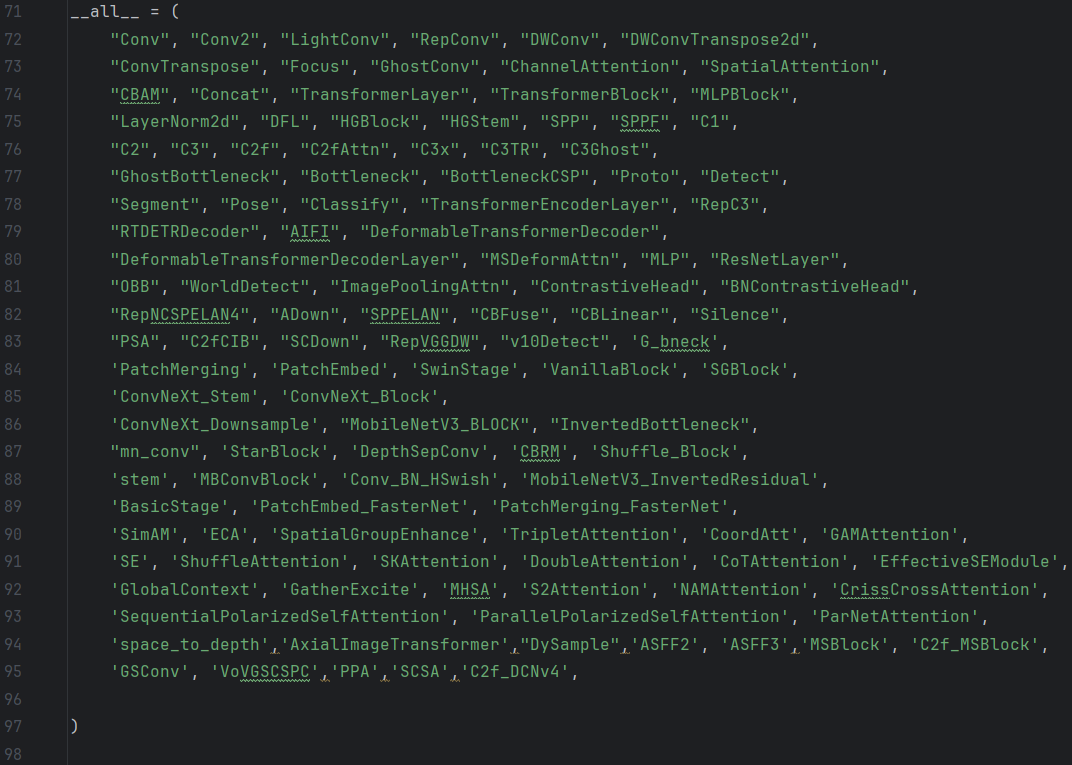
在ultralytics\nn\task.py中导包
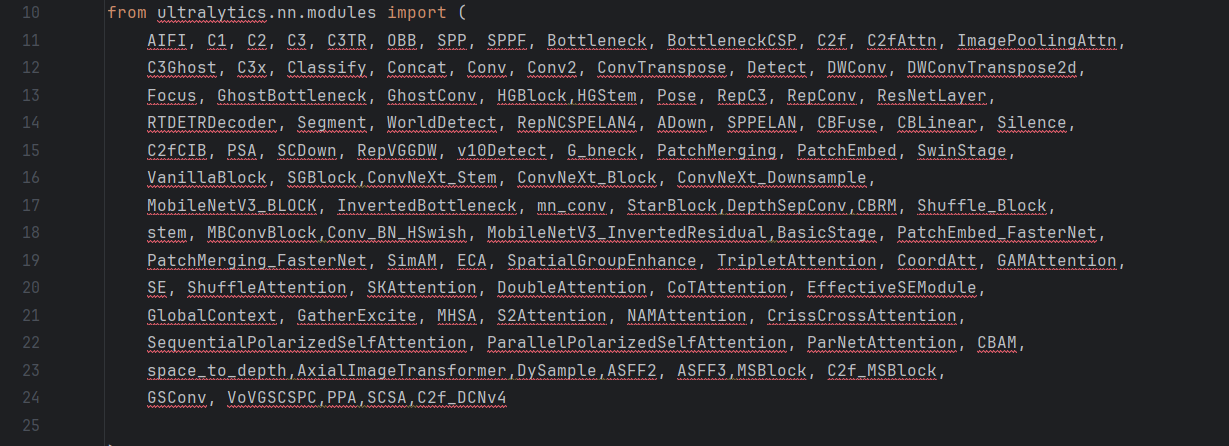
在task.py中添加模块C2f_DCNv4


继续在task中添加如下代码:
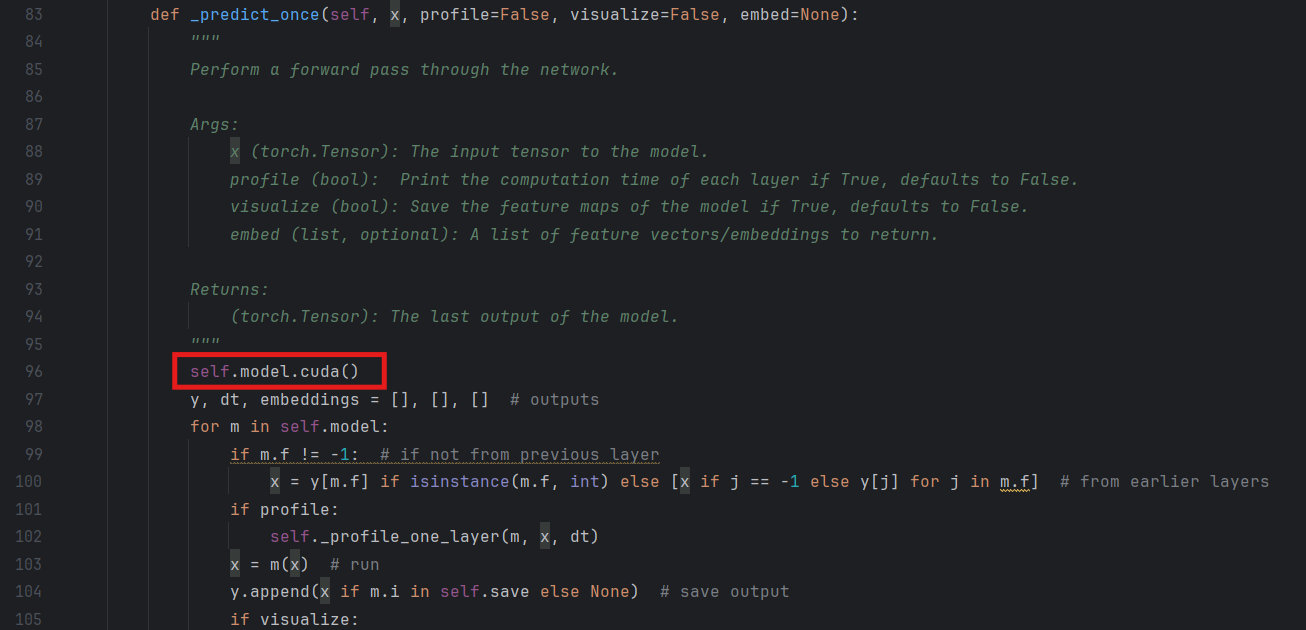
self.model.cuda()
继续在task.py中替换这行代码
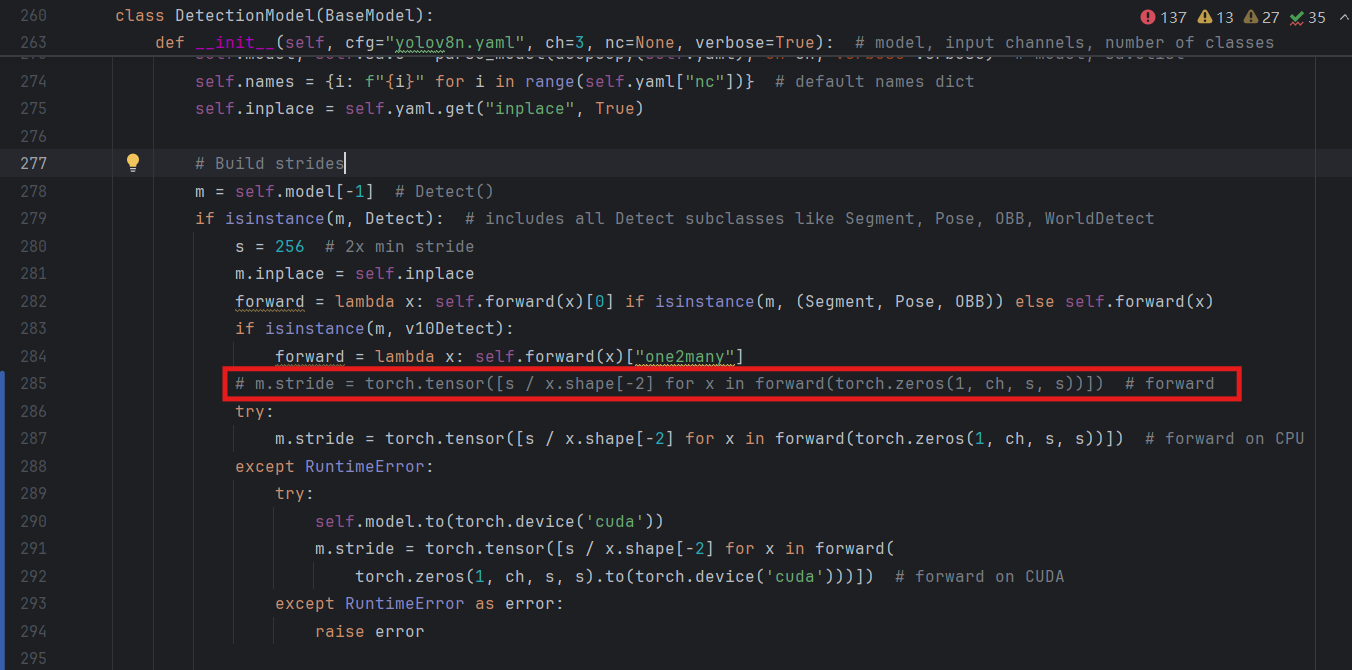
try:
m.stride = torch.tensor([s / x.shape[-2] for x in forward(torch.zeros(1, ch, s, s))]) # forward on CPU
except RuntimeError:
try:
self.model.to(torch.device('cuda'))
m.stride = torch.tensor([s / x.shape[-2] for x in forward(
torch.zeros(1, ch, s, s).to(torch.device('cuda')))]) # forward on CUDA
except RuntimeError as error:
raise error因DCNv4目前还不适配YOLO的图片维度,需要修改一下,将 ultralytics\nn\modules\DCNv4\DCNv4_op\DCNv4\modules\dcnv4.py 中的代码转为以下代码
# --------------------------------------------------------
# Deformable Convolution v4
# Copyright (c) 2023 OpenGVLab
# Licensed under The MIT License [see LICENSE for details]
# --------------------------------------------------------
from __future__ import absolute_import
from __future__ import print_function
from __future__ import division
import math
import torch
from torch import nn
import torch.nn.functional as F
from torch.nn.init import xavier_uniform_, constant_
from ..functions import DCNv4Function
class CenterFeatureScaleModule(nn.Module):
def forward(self,
query,
center_feature_scale_proj_weight,
center_feature_scale_proj_bias):
center_feature_scale = F.linear(query,
weight=center_feature_scale_proj_weight,
bias=center_feature_scale_proj_bias).sigmoid()
return center_feature_scale
class DCNv4(nn.Module):
def __init__(
self,
channels,
kernel_size=3,
stride=1,
pad=1,
dilation=1,
group=None,
offset_scale=1.0,
dw_kernel_size=None,
center_feature_scale=False,
remove_center=False,
output_bias=True,
without_pointwise=False,
**kwargs):
"""
DCNv4 Module
:param channels
:param kernel_size
:param stride
:param pad
:param dilation
:param group
:param offset_scale
:param act_layer
:param norm_layer
"""
super().__init__()
self.channels = channels
self.group = channels//16 if group is None else group
self.group_channels = self.channels // self.group
if self.channels % self.group != 0:
raise ValueError(
f'channels must be divisible by group, but got {self.channels} and {self.group}')
# _d_per_group = self.channels // self.group
# you'd better set _d_per_group to a power of 2 which is more efficient in our CUDA implementation
# assert _d_per_group % 16 == 0
self.offset_scale = offset_scale
self.kernel_size = kernel_size
self.stride = stride
self.dilation = dilation
self.pad = pad
self.offset_scale = offset_scale
self.dw_kernel_size = dw_kernel_size
self.center_feature_scale = center_feature_scale
self.remove_center = int(remove_center)
self.without_pointwise = without_pointwise
self.K = self.group * (kernel_size * kernel_size - self.remove_center)
if dw_kernel_size is not None:
self.offset_mask_dw = nn.Conv2d(channels, channels, dw_kernel_size, stride=1, padding=(dw_kernel_size - 1) // 2, groups=channels)
self.offset_mask = nn.Linear(channels, int(math.ceil((self.K * 3)/8)*8))
if not without_pointwise:
self.value_proj = nn.Linear(channels, channels)
self.output_proj = nn.Linear(channels, channels, bias=output_bias)
self._reset_parameters()
if center_feature_scale:
self.center_feature_scale_proj_weight = nn.Parameter(
torch.zeros((self.group, channels), dtype=torch.float))
self.center_feature_scale_proj_bias = nn.Parameter(
torch.tensor(0.0, dtype=torch.float).view((1,)).repeat(self.group, ))
self.center_feature_scale_module = CenterFeatureScaleModule()
def _reset_parameters(self):
constant_(self.offset_mask.weight.data, 0.)
constant_(self.offset_mask.bias.data, 0.)
if self.dw_kernel_size:
xavier_uniform_(self.offset_mask_dw.weight.data)
constant_(self.offset_mask_dw.bias.data, 0.)
if not self.without_pointwise:
xavier_uniform_(self.value_proj.weight.data)
constant_(self.value_proj.bias.data, 0.)
xavier_uniform_(self.output_proj.weight.data)
if self.output_proj.bias is not None:
constant_(self.output_proj.bias.data, 0.)
def forward(self, input):
"""
:param query (N, H, W, C)
:return output (N, H, W, C)
"""
b, c, h, w = input.shape
input = input
x = input.permute(0, 2, 3, 1).contiguous()
if not self.without_pointwise:
x = self.value_proj(x)
# x = x.reshape(b, h, w, -1)
if self.dw_kernel_size is not None:
offset_mask_input = self.offset_mask_dw(input)
offset_mask_input = offset_mask_input.permute(0, 2, 3, 1)#.view(b, h*w, -1)
else:
offset_mask_input = input.permute(0, 2, 3, 1)
offset_mask = self.offset_mask(offset_mask_input)#.reshape(b, h, w, -1)
x_proj = x
x = DCNv4Function.apply(
x, offset_mask,
self.kernel_size, self.kernel_size,
self.stride, self.stride,
self.pad, self.pad,
self.dilation, self.dilation,
self.group, self.group_channels,
self.offset_scale,
256,
self.remove_center
)
if self.center_feature_scale:
center_feature_scale = self.center_feature_scale_module(
x, self.center_feature_scale_proj_weight, self.center_feature_scale_proj_bias)
center_feature_scale = center_feature_scale[..., None].repeat(
1, 1, 1, 1, self.c // self.group).flatten(-2)
x = x * (1 - center_feature_scale) + x_proj * center_feature_scale
if not self.without_pointwise:
x = self.output_proj(x)
x = x.permute(0, 3, 1, 2)
return x
至此就可以将自己网络结构中的C2f改为C2F_DCNv4了
YOLOv10导入可变形卷积(DCNv4)
http://localhost:8090//archives/yolov10dao-ru-ke-bian-xing-juan-ji-dcnv4